Tecniche di commutazione
I componenti interni della rete sono costituiti da centri di commutazione e da canali che interconnettono i sistemi terminali di Internet.
La commutazione è la tecnica usata per assegnare un collegamento temporaneo a due interlocutori
Ad esempio, con riferimento alla figura seguente, un utente A che desidera entrare in comunicazione con un utente B raggiungibile al numero 210, compone la
prima cifra del numero (2) la quale viene usata per azionare il primo multiplexer. Quindi il suo telefono è collegato
sul filo di uscita numero 2 del primo multiplexer..
La seconda cifra composta dall'utente aziona il secondo commutatore in modo da collegare la sua linea di ingresso al
filo di uscita numero 1.
La terza cifra composta dall'utente aziona il terzo commutatore in modo da collegare la sua linea di ingresso al filo di uscita numero 0, che è direttamente collegato al telefono dell'utente B.

La commutazione di circuito riserva un canale fisico per la trasmissione. Le apparecchiature coinvolte nel collegamento non possono apportare alcun contributo alla comunicazione perchè svolgono solo il compito di deviatori.
Commutazione di pacchetto
Caratteristiche della commutazione di pacchetto
I pacchetti successivi di una stessa comunicazione possono seguire percorsi diversi e quindi giungono al ricevitore con ritardi diversi. È un problema grave con le informazioni audio o video, che si manifesta con fastidiose pause durante l'ascolto o la visualizzazione.
Il canale non è assegnato staticamente a due utenti ma è condiviso tra più utenti: sullo stesso canale, in istanti successivi, viaggiano i pacchetti di comunicazioni diverse (il canale si dice multiplexato).
Se un percorso è interrotto o è saturato la rete è in grado di scegliere un percorso alternativo.
La tariffazione può avvenire sul volume del traffico.
In una applicazione di rete, i sistemi terminali scambiano messaggi l'uno con l'altro. I messaggi possono contenere qualsiasi cosa il progettista dell'applicazione vuole. I messaggi possono svolgere una funzione di controllo (per esempio, i messaggi "Ciao" dell'esempio di sincronizzazione) o possono contenere dati, ad esempio un messaggio di posta elettronica, un'immagine JPEG, o un file audio MP3. Per inviare un messaggio da un sistema di origine a un sistema terminale di destinazione, la sorgente scompone i messaggi in blocchi di dati più piccoli noti come pacchetti. Tra sorgente e destinazione, ogni pacchetto viaggia attraverso canali di comunicazione e sistemi intermedi (router e switch). I pacchetti vengono trasmessi su ciascun canale ad una velocit` pari alla massima velocità di trasmissione del canale. Quindi, se un sistema sorgente o un switch sta inviando un pacchetto di L bit su un canale con velocità di trasmissione R bit/sec, il tempo per trasmettere il pacchetto è L/R secondi.
Trasmissione Store-and-Forward
Molti switch utilizzano la trasmissione store-and-forward. Trasmissione store-and-forward significa che il switch deve ricevere l'intero pacchetto prima che possa iniziare a trasmettere il primo bit del pacchetto sul canale in uscita. Per esaminare la trasmissione store-and-forward più in dettaglio, si consideri una rete semplice costituita da due sistemi terminali collegati da un singolo router, come illustrato nella figura.

Un router ha molti collegamenti. Il suo compito è quello di ricevere un pacchetto su un collegamento e trasmetterlo su un altro collegamento; in questo semplice esempio, il router ha il compito, piuttosto semplice, di trasferire un pacchetto da un canale (ingresso) all'unico altro canale. La sorgente ha tre pacchetti, ognuno composto da L bit, da inviare alla destinazione. All'istante di tempo mostrato in figura, la sorgente ha trasmesso parte del pacchetto 1, e la parte iniziale del pacchetto 1 è già arrivata al router. Poichè il router impiega la tecnica store and forward, in questo istante di tempo il router non può trasmettere i bit che ha ricevuto; invece deve prima memorizzare i bit del pacchetto. Solo dopo che il router ha ricevuto (store) tutti i bit del pacchetto può cominciare a trasmettere (forward) il pacchetto sul canale in uscita.
Si calcoli il tempo che trascorre da quando la sorgente inizia ad inviare il pacchetto fino a quando il destinatario ha ricevuto l'intero pacchetto. Si ignorerà il tempo necessario ai bit per viaggiare attraverso il filo a velocità prossime a quelle della luce. La sorgente inizia a trasmettere al tempo 0; al tempo L/R secondi, la sorgente ha trasmesso l'intero pacchetto, e l'intero pacchetto è stato ricevuto e memorizzato dal router (poichè non vi è alcun ritardo di propagazione). Al tempo L/R secondi, poichè il router ha appena ricevuto l'intero pacchetto, può cominciare a trasmettere il pacchetto sul canale in uscita verso la destinazione; al tempo 2·L/R, il router ha trasmesso l'intero pacchetto, e l'intero pacchetto è stato ricevuto dalla destinazione. Così, il ritardo totale è 2·L/R. Se il router trasmettesse i bit appena arrivano (senza prima ricevere l'intero pacchetto), allora il ritardo totale sarebbe L/R. Ma i router hanno bisogno di ricevere, memorizzare ed elaborare l'intero pacchetto prima di inoltrarlo.
Ora si calcoli il tempo che trascorre da quando la sorgente inizia ad inviare il primo pacchetto fino a quando la destinazione ha ricevuto i tre pacchetti. Come prima, al tempo L/R, il router inizia a trasmettere il primo pacchetto. Ma all'istante L/R la sorgente inizierà ad inviare anche il secondo pacchetto, dato che ha appena finito di inviare l'intero primo pacchetto. Così, al tempo 2·L/R, la destinazione ha ricevuto il primo pacchetto e il router ha ricevuto il secondo pacchetto. Analogamente, al tempo 3·L/R, la destinazione ha ricevuto i primi due pacchetti e il router ha ricevuto il terzo pacchetto. Infine, al tempo 4·L/R la destinazione ha ricevuto tutti e tre i pacchetti.
Si consideri il caso generale dell'invio di un pacchetto da una sorgente ad una destinazione su un percorso costituito da N canali, ciascuno di capacità R (quindi, ci sono N-1 router tra sorgente e destinazione). Applicando la stessa logica di prima, si vede che il ritardo end-to-end è:
dend-to-end = N·L/R
In questo modo si può determinare il ritardo subito da P pacchetti che attraversano N canali.
Ritardo nelle code e perdita di pacchetti.
Ad ogni switch o router sono collegati più canali. Per ogni canale il switch ha un buffer di uscita (o anche coda di uscita), che memorizza i pacchetti che il router è in procinto di inviare su quel link. I buffer di uscita giocano un ruolo chiave nella commutazione di pacchetto. Se un pacchetto in arrivo deve essere trasmesso su un canale ma la connessione è occupata con la trasmissione di un altro pacchetto, il pacchetto in arrivo deve attendere nel buffer di uscita. Pertanto, in aggiunta al ritardo store-and-forward, i pacchetti subiscono un ritardo nella coda in attesa di essere trasmessi. Questi ritardi sono variabili e dipendono dal traffico della rete. Poichè la quantità di spazio nel buffer è finita, un pacchetto in arrivo potrebbe trovare il buffer completamente pieno di pacchetti in attesa di trasmissione. In questo caso, si verificherà la perdita di pacchetti, ovvero il pacchetto in arrivo verrà scartato o uno dei pacchetti in coda verrà sovrascritto.
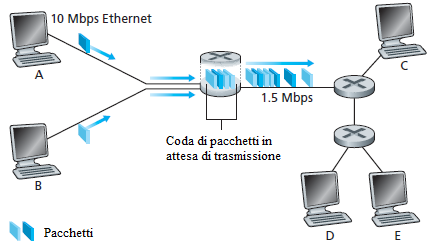
La figura illustra una semplice rete a commutazione di pacchetto. I pacchetti sono rappresentati da buste. La larghezza di una busta rappresenta il numero di bit nel pacchetto. In questa figura, tutti i pacchetti hanno la stessa lunghezza. Si suppone che gli host A e B inviano pacchetti all'host E. Gli host A e B inviano i loro pacchetti lungo il canale Ethernet a 10 Mbps al primo router. Il router smista poi questi pacchetti sul canale a 1,5 Mbps. Se, durante un breve intervallo di tempo, il tasso di arrivo dei pacchetti al router (convertito in bit per secondo) è superiore a 1,5 Mbps, si verificherà la congestione al router perchè la coda dei pacchetti nel buffer di uscita del canale si svuota meno rapidamente. Ad esempio, se gli host A e B inviano contemporaneamente ciascuno una raffica di cinque pacchetti uno dietro l'altro, allora la maggior parte di questi pacchetti resteranno un certo tempo nella coda prima di essere smistati. La situazione è, infatti, del tutto analoga a molti casi comuni ad esempio quando si aspetta in coda ad uno sportello in attesa di essere serviti.
Tabelle di instradamento e protocolli di instradamento
Un router riceve un pacchetto su uno dei suoi canali e lo smista su un altro. Ma come fa il router a determinare su quale canale deve inoltrare il pacchetto? Lo smistamento dei pacchetti è realizzato in modi diversi nei diversi tipi di reti di computer. Si descriverà brevemente la soluzione in Internet.
In Internet, ogni sistema terminale ha un indirizzo chiamato indirizzo IP. Quando un sistema sorgente vuole inviare un pacchetto a un sistema terminale di destinazione, la sorgente include l'indirizzo IP di destinazione nell'intestazione del pacchetto. Come con gli indirizzi postali, questo indirizzo ha una struttura gerarchica. Quando un pacchetto arriva a un router in rete, il router esamina l'indirizzo di destinazione del pacchetto e inoltra il pacchetto a un router adiacente. Più precisamente, ogni router ha una tabella di instradamento che contiene la corrispondenza tra gli indirizzi di destinazione e le linee di uscita del router. Quando un pacchetto arriva ad un router, il router esamina l'indirizzo e cerca nella sua tabella di instradamento la riga avente quell'indirizzo di destinazione, per trovare il link in uscita appropriato. Il router trasmette il pacchetto su questo link, allo scopo di farlo giungere alla destinazione corretta.
Il processo di instradamento da un sistema terminale ad un altro è analogo ad un automobilista che non usa le mappe, ma preferisce chiedere indicazioni. Ad esempio, si supponga che Joe sia un turista che parte da Bari per recarsi a via Roma, 76 di Caserta. Joe raggiunge un distributore di benzina nella zona di Bari e chiede come arrivare a via Roma, 76 di Caserta. Il benzinaio estrae la parte Caserta dell'indirizzo e dice a Joe che ha bisogno di prendere l'autostrada A14 in direzione Napoli, e uscire a Caserta Nord, dove deve chiedere a qualcun altro. Joe prende la A14 ed esce a Caserta, a quel punto chiede a un altro benzinaio come raggiungere l'indirizzo che cerca. L'addetto estrae la parte Caserta dall'indirizzo e dice a Joe che deve continuare sulla via Appia e poi chiedere a qualcun altro. Arrivato all'incrocio, un passante gli indica come raggiungere via Roma. Una volta che Joe raggiunge via Roma, chiede ad un bambino su una bicicletta come raggiungere la sua destinazione. Il ragazzo estrae la parte 76 dall'indirizzo e indica la casa. Joe raggiunge finalmente la sua destinazione finale. I benzinai, i passanti e bambini in bicicletta sono analoghi ai router.
Un router utilizza l'indirizzo di destinazione di un pacchetto come indice di accesso alla tabella di instradamento e determina il link in uscita appropriato. Ma questa definizione pone un'altra domanda: Come vengono costruite le tabelle di instradamento? Sono configurate a mano in ogni router, o esiste un procedimento automatico? Per adesso si noti che Internet ha una serie di protocolli di routing speciali che vengono utilizzati per costruire automaticamente le tabelle di instradamento. Un protocollo di routing può, ad esempio, determinare i percorsi più brevi da ogni router a ciascuna destinazione e utilizzare i cammini meno costosi per configurare le tabelle di instradamento nei router.
Visitare il sito www.traceroute.org, scegliere una sorgente in un determinato paese, e tracciare il percorso da quella sorgente al proprio computer.
Commutazione di circuito
Ci sono due approcci fondamentali per trasferire dati attraverso una rete di collegamenti e switch: la commutazione di circuito e la commutazione di pacchetto. Le reti a commutazione di pacchetto sono state descritte nel paragrafo precedente, in questo paragrafo si descriveranno le reti a commutazione di circuito.
Nelle reti a commutazione di circuito, le risorse necessarie (buffer, capacità del canale) per fornire la comunicazione tra i sistemi terminali sono riservate per la durata della sessione di comunicazione tra i sistemi terminali. Nelle reti a commutazione di pacchetto, queste risorse non sono riservate; i messaggi di una sessione utilizzano le risorse su richiesta, e di conseguenza, può essere necessario attendere (cioè restare in coda) per l'accesso ad un canale di comunicazione. Come una semplice analogia, si considerino due ristoranti, uno che richiede la prenotazione e un altro che non accetta prenotazioni. Per il ristorante che richiede prenotazioni, si deve chiamare prima di uscire da casa. Quando si arriva al ristorante si può, in linea di principio, occupare immediatamente il tavolo e ordinare. Per il ristorante che non richiede prenotazioni, non c'è bisogno di preoccuparsi di prenotare un tavolo. Ma quando si arriva al ristorante, si potrebbe dover aspettare prima che si liberi un tavolo.
Le reti telefoniche tradizionali sono esempi di reti a commutazione di circuito. Si consideri che cosa accade quando una persona vuole inviare informazioni (voce o fax) ad un altro utente attraverso la rete telefonica. Prima che il mittente possa inviare informazioni, la rete deve stabilire una connessione tra il mittente e il destinatario. Questa è una connessione affidabile nella quale le centrali sul percorso tra il mittente e il destinatario mantengono lo stato della connessione. Nel gergo della telefonia, questa connessione è chiamata circuito. Quando la rete stabilisce il circuito, assegna anche una velocità di trasmissione costante (che rappresenta una frazione della capacità di trasmissione di ciascun link) per tutta la durata della connessione. Poichè un dato tasso di trasmissione è stato riservato per questa connessione dal mittente al destinatario, il mittente può trasferire i dati al ricevitore ad un tasso costante garantito.
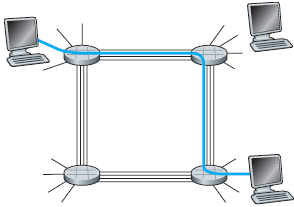
La figura illustra una rete a commutazione di circuito, nella quale le quattro centrali di commutazione sono collegate con dei canali. Ciascuno di questi canali ha quattro circuiti, in modo che ogni canale può supportare quattro connessioni simultanee. Gli host (PC e workstation) sono collegati direttamente a una delle centrali. Quando due host vogliono comunicare, la rete stabilisce una connessione dedicata end-to-end tra i due host. Pertanto, al fine di consentire all'host A di comunicare con l'host B, la rete deve prima prenotare un circuito su ciascuno dei due collegamenti. In questo esempio, la connessione dedicata end-to-end utilizza il secondo circuito del primo canale e il quarto circuito nel secondo canale. Poichè ogni canale ha quattro circuiti, per ogni canale utilizzato dalla connessione end-to-end, la comunicazione ottiene un quarto della capacità totale di trasmissione del canale per la durata della trasmissione. Ad esempio, se ogni canale tra centrali adiacenti ha una velocità di trasmissione di 1 Mbps, allora ad ogni circuito end-to-end viene dedicata la velocità di trasmissione di 250 kbps.
Al contrario, si consideri cosa accade quando un host vuole inviare un pacchetto a un altro host su una rete a commutazione di pacchetto, come Internet. Come con la commutazione di circuito, il pacchetto viene trasmesso su una serie di canali di comunicazione. Ma a differenza dalla commutazione di circuito, il pacchetto viene inviato in rete, senza riservare alcuna risorsa. Se uno dei link è congestionato perchè altri pacchetti devono essere trasmessi sul collegamento, allora il pacchetto dovrà attendere in un buffer sul lato di trasmissione e subire dei ritardi. Internet fa del suo meglio per consegnare i pacchetti in modo tempestivo, ma non fornisce alcuna garanzia.
Il Multiplexing nelle reti a commutazione di circuito
Un canale, o circuito, può essere utilizzato con la multiplazione a divisione di frequenza (FDM) o con la multiplazione a divisione di tempo (TDM). Con FDM, lo spettro di frequenza di un collegamento è suddiviso tra le connessioni stabilite sul collegamento.
In particolare, il collegamento dedica una banda di frequenza a ciascuna connessione per la durata della comunicazione. Nelle reti telefoniche, questa banda di frequenza ha una larghezza di 4 kHz, ed è detta appunto larghezza di banda. Le stazioni radio FM usano la tecnica FDM per condividere lo spettro di frequenze comprese tra 88 MHz e 108 MHz, in cui ad ogni stazione viene assegnata una specifica banda di frequenza.
Per un collegamento TDM, il tempo è diviso in frame di durata fissa, e ognuno di questi è diviso in un numero fisso di slot. Quando la rete stabilisce una connessione attraverso un canale, la rete dedica un time slot in ogni frame per questa connessione. Questi slot sono dedicati ad uso esclusivo di tale connessione: un solo slot è disponibile in ogni frame per trasmettere i dati della connessione.
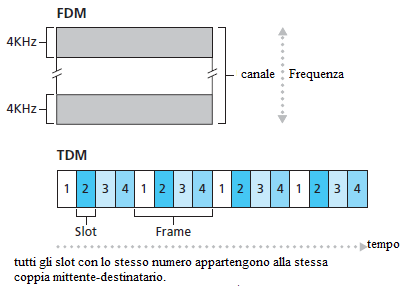
La figura mostra le tecniche FDM e TDM per un collegamento specifico che supporta fino a quattro circuiti. Per FDM, il dominio della frequenza è segmentato in quattro gruppi, ciascuno di larghezza di banda di 4 kHz. Per TDM, il dominio del tempo è segmentato in frame, con quattro intervalli di tempo in ogni frame; ad ogni circuito viene assegnato lo stesso slot all'interno dei frame TDM. Quindi un circuito usa solo periodicamente tutta la banda, per un breve intervallo di tempo. Con TDM, la velocità di trasmissione di un circuito è uguale alla frequenza di frame moltiplicata per il numero di bit in uno slot. Ad esempio, se il canale trasmette 8.000 frame/sec e ogni slot &è di 8 bit, allora la velocità di trasmissione di un circuito è di 64 kbps.
Uno dei difetti della commutazione di circuito è che i circuiti sono inattivi durante le pause della comunicazione. Ad esempio, quando una persona in una telefonata smette di parlare, le risorse di rete (bande di frequenza o slot di tempo nei canali lungo il percorso) non possono essere utilizzate da altre connessioni in corso. Come altro esempio di come queste risorse possono essere sottoutilizzate, si consideri un radiologo che utilizza una rete a commutazione di circuito per accedere da remoto ad una serie di radiografie. Il radiologo imposta una connessione, richiede un'immagine, contempla l'immagine, e quindi richiede una nuova immagine. Le risorse di rete sono assegnate alla connessione, ma non vengono utilizzate (vale a dire, si sprecano) durante i periodi di contemplazione del radiologo. Anche la tecnica di commutazione per assegnare i circuiti ad una comunicazione è complicata e richiede software di segnalazione complessi per coordinare il funzionamento degli switch lungo il percorso end-to-end.
Prima di terminare la discussione sulla commutazione di circuito, si consideri un esempio numerico che dovrebbe fare ulteriore chiarezza sull'argomento. Si calcoli il tempo necessario per inviare un file di 640.000 bit dall'host A all'host B su una rete a commutazione di circuito. Si supponga che tutti i canali usino TDM con 24 slot e hanno una velocità di 1.536 Mbps. Si supponga inoltre che siano richiesti 500 ms per stabilire un circuito end-to-end prima che l'host A possa cominciare a trasmettere il file. Quanto tempo ci vuole per inviare il file? Ogni circuito ha una velocità di trasmissione di (1,536 Mbps)/24 = 64 kbps, quindi occorrono (640.000 bits) / (64 kbps) = 10 secondi per trasmettere il file. A questi 10 secondi si aggiunga il tempo di creazione del circuito, quindi occorrono 10,5 secondi per inviare il file. Si noti che il tempo di trasmissione è indipendente dal numero di collegamenti: Il tempo di trasmissione è di 10 secondi sia se il circuito end-to-end è formato da un unico collegamento sia se è formato da cento canali. (L'effettivo ritardo end-to-end comprende anche un ritardo di propagazione).
Confronto tra commutazione di circuito e commutazione di pacchetto
Dopo aver descritto la commutazione di circuito e la commutazione di pacchetto, si confrontino le due tecniche. Qualcuno sostiene che la commutazione di pacchetto non è adatta per i servizi in tempo reale (per esempio, telefonate e video conferenze) a causa dei ritardi variabili e imprevedibili (soprattutto quelli subiti nelle code). La commutazione di pacchetto (1) offre una migliore ripartizione della capacità di trasmissione rispetto alla commutazione di circuito e (2) è più semplice, più efficiente e meno costosa da implementare della commutazione di circuito. In generale, le persone che non amano complicarsi la vita con prenotazioni al ristorante preferiscono la commutazione di pacchetto alla commutazione di circuito.
Perchè la commutazione di pacchetto è più efficiente? Si consideri il seguente esempio, basato sulle seguenti ipotesi:
gli utenti condividono un collegamento di 1 Mbps.
ogni utente alterna periodi di attività, quando genera dati a una velocità costante di 100 kbps, e periodi di inattività, quando non genera alcun dato.
un utente è attivo solo il 10 per cento del tempo.
Con la commutazione di circuito, 100 kbps devono essere riservati ad ogni utente in ogni momento. Ad esempio, con la commutazione di circuito TDM, se un frame di un secondo è diviso in 10 intervalli di tempo di 100 ms ciascuno, allora ad ogni utente dovrebbe essere assegnato un time slot per frame. Così, il collegamento a commutazione di circuito può supportare solo 10 (= 1 Mbps/100 kbps) utenti simultanei.
Con la commutazione di pacchetto, la probabilità che un utente specifico sia attivo è 0,1 (cioè, il 10 per cento). Se ci sono 35 utenti, la probabilità che ci siano 11 o più utenti contemporaneamente attivi è circa 0,0004. Quando ci sono 10 o meno utenti attivi contemporaneamente (il che accade con probabilità 0,9996), la velocità dei dati è inferiore o uguale alla capacità del canale di 1 Mbps. Così, quando ci sono 10 o meno utenti attivi, i pacchetti degli utenti scorrono attraverso il collegamento alla massima velocità, come è il caso con la commutazione di circuito. Quando ci sono più di 10 utenti attivi contemporaneamente, allora la frequenza di pacchetti entranti supera la capacità del canale su cui dovranno essere trasmessi, e la coda di uscita comincerà a crescere. (Continua a crescere fino a quando la frequenza dei pacchetti in entrata si porta al di sotto della velocità di 1 Mbps, a quel punto la coda inizierà a diminuire in lunghezza). Poichè la probabilità di avere più di 10 utenti contemporaneamente attivi è trascurabile in questo esempio, la commutazione di pacchetto prevede essenzialmente le stesse prestazioni della commutazione di circuito, ma consente più di tre volte il numero di utenti.
Come secondo esempio si supponga che ci siano 10 utenti e che un utente generi improvvisamente mille pacchetti di 1.000 bit, mentre gli altri utenti rimangono quiescenti e non generano pacchetti. Con la commutazione di circuito TDM con 10 slot per frame e ogni slot consistente di 1.000 bit, l'utente attivo può usare solo il suo slot per frame per trasmettere i dati, mentre i restanti nove slot in ogni frame restano vuoti. Sono richiesti 10 secondi prima che tutto un milione di bit dei dati dell'utente attivo siano trasmessi. Nel caso della commutazione di pacchetto, l'utente attivo può inviare continuamente i pacchetti alla velocità massima di 1 Mbps, poichè non ci sono altri utenti che generano pacchetti e che devono essere multiplati con i pacchetti dell'utente attivo. In questo caso, tutti i dati dell'utente attivo saranno trasmessi in 1 secondo.
Gli esempi precedenti illustrano due casi in cui le prestazioni della commutazione di pacchetto possono essere superiori a quelle della commutazione di circuito. Hanno anche evidenziato la differenza fondamentale tra le due forme di condivisione della velocità di trasmissione di un collegamento tra più flussi di dati. La Commutazione di circuito assegna in anticipo l'utilizzo della linea di trasmissione a prescindere dalla richiesta, ma il canale non è utilizzato per tutta la durata della comunicazione. La commutazione di pacchetto invece assegna il canale su richiesta. La capacità di trasmissione del collegamento sarà condivisa solo tra gli utenti che hanno pacchetti da trasmettere.
Sebbene la commutazione di pacchetto e la commutazione di circuito siano entrambe presenti nelle reti di telecomunicazioni odierne, la tendenza è stata certamente nella direzione della commutazione di pacchetto. Anche molte delle reti telefoniche a commutazione di circuito odierne stanno lentamente migrando verso la commutazione di pacchetto.
Caratteristiche della commutazione di circuito
Il circuito è trasparente ai segnali che l'attraversano: non è in grado di interpretarli.
Il circuito resta riservato agli utenti collegati per tutta la durata della comunicazione e non può essere utilizzato da nessun altro.
La rete è dimensionata per sostenere un traffico massimo previsto per le ore di punta e quindi è sottoutilizzata durante le altre ore.
Il circuito introduce lo stesso ritardo su tutte le parti del messaggio. Questo è un effetto positivo.
La commutazione di pacchetto
I nodi non sono dei semplici deviatori ma sono dei sistemi dotati di memoria e di CPU.
Mentre la commutazione di circuito è adatta per il trasferimento di informazioni analogiche, la commutazione di pacchetto è in grado di trasportare solo informazioni digitali.
Il messaggio viene frammentato in unità di dimensioni prefissate, dette pacchetti, e corredate da un'intestazione che contiene le informazioni necessarie a consentire la corretta consegna al destinatario.
I nodi leggono l'intestazione di ogni pacchetto e decidono la linea di uscita su cui smistare il pacchetto.

I nodi, indicati in rosso, hanno il compito di leggere l'intestazione dei pacchetti, indicati con un numero racchiuso in un quadrato, e smistarli fino a consegnarli al destinatario.
La figura mostra:
su uno stesso canale viaggiano pacchetti di utenti diversi;
pacchetti di uno stesso utente possono seguire percorsi diversi.
Una Rete di reti
I sistemi terminali (PC, smartphone, server Web, server di posta elettronica, ecc.) si collegano ad Internet tramite un ISP. L'ISP fornisce la connettività sia cablata sia wireless, utilizzando una serie di tecnologie tra cui DSL, via cavo, FTTH, Wi-Fi e cellulare. Si noti che il provider potrebbe non essere un gestore della telefonia o una TV via cavo; invece può essere, per esempio, una università (che fornisce l'accesso a Internet a studenti, personale e docenti), o di una azienda (che fornisce accesso per i propri dipendenti). Ma il collegamento degli utenti finali e dei fornitori di contenuti ad un provider è solo un piccolo problema rispetto a quello di collegare i miliardi di sistemi terminali che compongono Internet. Per completare questo mosaico, gli stessi provider devono essere interconnessi. Questo viene fatto attraverso la creazione di una rete di reti. La comprensione di questa frase è la chiave per comprendere Internet.
Nel corso degli anni, la rete delle reti che forma Internet si è evoluta in una struttura molto complessa. Gran parte di questa evoluzione è guidata da motivi economici e politici, piuttosto che da considerazioni sulle prestazioni. Al fine di comprendere la struttura della rete Internet di oggi, in questo paragrafo si descrive, in modo progressivo, una serie di strutture di rete, dove ogni nuova struttura è una migliore approssimazione di Internet. L'obiettivo primario è quello di interconnettere gli ISP in modo che tutti i sistemi terminali possano scambiare pacchetti. Un approccio ingenuo sarebbe quello di avere ogni ISP connesso direttamente con tutti gli altri ISP. Tale disegno a griglia è, ovviamente, troppo costoso per gli ISP, in quanto richiederebbe che ogni ISP abbia un collegamento separato per ciascuna delle centinaia di migliaia di altri provider in tutto il mondo.
La prima struttura di rete, Struttura Rete 1, collega tutti i fornitori di servizi Internet con un singolo ISP globale. Un (immaginario) ISP globale è una rete di router e canali di comunicazione che non solo si estende nel mondo, ma ha anche almeno un router in corrispondenza di ciascuna delle centinaia di migliaia di ISP. Naturalmente, sarebbe molto costoso per il provider globale costruire una tale vasta rete. Per essere conveniente, ciascuno dei provider dovrebbe tariffare gli utenti con il volume di traffico che un ISP scambia con l'ISP globale. Dal momento che l'ISP paga l'ISP globale, l'ISP è detto essere un cliente e l'ISP globale, si dice che sia un fornitore.
Di conseguenza risulta economicamente conveniente per un'azienda costruire e gestire un ISP globale, ma è anche naturale per le altre società costruire i propri fornitori di servizi Internet globali e competere con l'ISP globale originale. Questo porta alla Struttura Rete 2, che consiste delle centinaia di migliaia di ISP più l'ISP globale. Gli ISP preferiscono la Struttura Rete 2 alla Struttura Rete 1 perchè possono scegliere tra i fornitori globali in funzione delle loro tariffe e servizi. Si noti, tuttavia, che gli ISP globali devono interconnettersi: In caso contrario gli ISP collegati ad uno dei fornitori globali non sarebbero in grado di comunicare con gli ISP collegati agli altri fornitori globali.
La Struttura Rete 2, appena descritta, è una gerarchia a due livelli con fornitori globali che risiedono alla radice e gli ISP al livello inferiore. Questo presuppone che gli ISP globali sono direttamente collegati ad un ISP. In realtà, anche se alcuni ISP hanno una copertura globale e non sono collegati direttamente con altri ISP, nessun ISP è presente in ogni città del mondo. Invece, in qualsiasi data regione, ci può essere un ISP regionale a cui gli ISP della regione si connettono. Ogni ISP regionale si collega all'ISP di primo livello. Gli ISP di primo livello sono simili all'ISP (immaginario) globale; ma gli ISP di primo livello, che in realtà non esistono, non hanno una presenza in ogni città del mondo.
Tornando a questa rete di reti, non solo ci sono più concorrenti ISP di primo livello, ma ci possono essere più concorrenti ISP regionali in una regione. In tale gerarchia, ogni ISP paga l'ISP regionale, a cui si collega, e ogni ISP regionale paga l'ISP a cui si connette. (Un ISP si può anche collegare direttamente a un ISP di primo livello, nel qual caso paga quell'ISP). Pertanto, non vi è rapporto cliente-fornitore a ogni livello della gerarchia. Si noti che gli ISP di primo livello non pagano nessuno perchè sono al vertice della gerarchia. A complicare ulteriormente le cose, in alcune regioni, ci può essere un grande ISP regionale a cui i più piccoli ISP regionali in quella zona si collegano; il più grande ISP regionale si collega all'ISP di primo livello. Ad esempio, in Cina, ci sono gli ISP in ogni città, che si collegano agli ISP provinciali, che a loro volta si collegano agli ISP nazionali, che finalmente si connettono all'ISP di primo livello. Questa gerarchia multi-livello, che è ancora solo una approssimazione grezza di Internet di oggi, viene riferita come la Struttura di Rete 3.
Per costruire una rete che somigli più da vicino a Internet di oggi, bisogna aggiungere punti di presenza (PoP), multi-homing, peering e Internet Exchange Point (IXP) alla Struttura della Rete 3. Esistono PoP in tutti i livelli della gerarchia, con esclusione del livello più basso (accesso ISP). Un PoP è semplicemente un gruppo di uno o più router (nello stesso luogo), nella rete del provider a cui gli ISP clienti possono connettersi al provider di servizi Internet. Affinchè una rete del cliente si connetta al PoP di un provider, può affittare un collegamento ad alta velocità da un provider di telecomunicazioni per collegare direttamente uno dei suoi router ad un router del PoP. Ogni ISP (ad eccezione dell'ISP di primo livello) può scegliere il multi-home, cioè connettersi a due o più fornitori di servizi Internet. Così, per esempio, un ISP può connettersi con due ISP regionali, o con due ISP regionali e con un ISP di primo livello. Analogamente, un ISP regionale può collegarsi con più ISP di primo livello. Questi collegamenti consentono ad un ISP di continuare a essere collegato a Internet anche se uno dei fornitori ha un guasto.
Gli ISP clienti pagano i loro fornitori di servizi Internet per ottenere l'interconnessione globale a Internet. L'importo che un ISP cliente paga a un ISP fornitore dipende dalla quantità di traffico che scambia con il provider. Per ridurre questi costi, una coppia di ISP limitrofi, allo stesso livello della gerarchia, possono collegare direttamente le loro reti in modo che tutto il loro traffico passi attraverso la connessione diretta piuttosto che tramite intermediari a monte. Come osservato in precedenza, anche gli ISP di primo livello collaborano uno con l'altro. Lungo queste stesse linee, una società di terze parti in grado di creare un Internet Point of Exchange (IXP) (tipicamente in un edificio autonomo con propri switch), che è un punto di incontro dove più ISP possono connettersi. Ci sono circa 300 IXP in Internet oggi. Questo ecosistema composto da ISP, ISP regionali, ISP di primo livello, PoP, multi-homing, peering, e IXP viene riferito come la Struttura di Rete 4.
La Struttura di Rete 5, che descrive Internet del 2012, si basa sulla parte superiore della struttura Rete 4 con l'aggiunta di reti di fornitori di contenuti. Google è attualmente uno dei principali esempi di una tale rete di fornitore di contenuti. Si stima che Google ha da 30 a 50 data center distribuiti in tutto il Nord America, Europa, Asia, Sud America e Australia. Alcuni di questi data center ospitano oltre centomila server, mentre gli altri centri dati sono più piccoli, ospitano solo centinaia di server. I centri dati di Google sono tutti interconnessi tramite rete privata TCP/IP di Google, che copre il mondo intero, ma è comunque separata dalla rete Internet pubblica. È importante sottolineare che la rete privata di Google porta solo il traffico da/a i server di Google. La rete privata di Google cerca di raggirare i livelli superiori di Internet connettendosi direttamente con gli ISP di livello inferiore. Tuttavia, poichè molti ISP possono ancora essere raggiunti solo da reti di primo livello, la rete di Google si collega anche all'ISP di primo livello, e paga i provider per il traffico scambiato con loro. Con la creazione di una propria rete, un fornitore di contenuti non solo riduce i costi agli ISP di livello superiore, ma ha anche un maggiore controllo su come i suoi servizi sono offerti agli utenti finali.
In sintesi, oggi Internet - una rete di reti - è complessa, costituita da una decina di ISP di primo livello e centinaia di migliaia di ISP di livello inferiore. Gli ISP differiscono per la loro copertura, alcuni coprono vari continenti, e altri limitate regioni geografiche. Gli ISP di livello inferiore si collegano agli ISP di livello superiore, e un ISP di livello superiore si connette con un altro. Gli utenti e i fornitori di contenuti sono clienti di un ISP di livello inferiore, e gli ISP di livello inferiore sono clienti di un ISP di livello superiore. Negli ultimi anni, i principali fornitori di contenuti hanno anche creato le proprie reti collegate direttamente ad un ISP di livello inferiore, ove possibile.
Ritardi, Perdite e Flusso nelle reti a commutazione di pacchetto
La rete Internet può essere vista come un'infrastruttura che fornisce servizi alle applicazioni distribuite, in esecuzione su sistemi terminali. Idealmente, si vorrebbe che i servizi Internet siano in grado di trasferire i dati tra due sistemi terminali, istantaneamente, senza alcuna perdita di dati. Questo è un obiettivo ambizioso, irraggiungibile nella realtà. Invece, le reti informatiche necessariamente limitano il throughput (quantità di dati al secondo che vengono trasferiti) tra sistemi terminali, introducono ritardi tra i sistemi terminali, e possono effettivamente perdere pacchetti. Da un lato, è un peccato che le leggi fisiche introducano ritardi e perdite, e vincolino il throughput. D'altra parte, poichè le reti di computer hanno questi problemi, ci sono molte interessanti questioni relative al modo di affrontarli. In questa sezione si esaminano e si quantificano il ritardo, la perdita e il throughput nelle reti di computer.
Cause dei ritardi nelle reti a commutazione di pacchetto.
Un pacchetto parte da un host (sorgente), passa attraverso una serie di router, e termina il suo viaggio in un altro host (destinazione). Durante il viaggio da un nodo (host o router) al successivo nodo (host o router) il pacchetto subisce diversi tipi di ritardo in ogni nodo che attraversa. I più importanti di questi ritardi sono il ritardo di elaborazione, il ritardo di attesa in coda, il ritardo di trasmissione, e il ritardo di propagazione; insieme, questi ritardi si accumulano per dare un ritardo totale di nodo. Le prestazioni di molte applicazioni Internet come la ricerca, la navigazione Web, l'e-mail, le mappe, l'instant messaging e il voice-over-IP risentono moltissimo di questi ritardi di rete. Al fine di acquisire una conoscenza approfondita della commutazione di pacchetto e delle reti di computer, si deve comprendere la natura e l'importanza di questi ritardi.
Tipi di ritardo
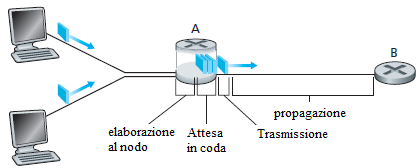
In questo paragrafo si analizzano questi ritardi con riferimento alla figura precedente. Come parte del suo percorso end-to-end tra sorgente e destinazione, un pacchetto viene inviato da un nodo attraverso il router A al router B. Si vogliono determinare le cause del ritardo di nodo al router A. Il router A ha un link in uscita che conduce al router B. Questo collegamento è preceduto da una coda (o buffer). Quando il pacchetto arriva al router A dal nodo precedente, il router A esamina l'intestazione del pacchetto per determinare il collegamento in uscita appropriato su cui il pacchetto deve proseguire il proprio cammino e quindi trasmette il pacchetto su questo link. In questo esempio, il collegamento in uscita per il pacchetto è quello che porta al router B. Un pacchetto può essere trasmesso su un link solo se non vi è un altro pacchetto attualmente trasmesso sul link e se non vi sono altri pacchetti che lo precedono nella coda; se il collegamento è occupato o se ci sono altri pacchetti già in coda in attesa di essere trasmessi su quel link, il pacchetto appena arrivato dovrà essere inserito nella coda.
Ritardo di elaborazione
Il tempo necessario per esaminare l'intestazione del pacchetto e determinare dove indirizzare il pacchetto è parte del ritardo di elaborazione. Il ritardo di elaborazione può includere anche altri fattori, come il tempo necessario per verificare la presenza di errori a livello di bit, che il pacchetto potrebbe avere subito durante la propagazione sul canale che porta al router A. I ritardi di elaborazione dei router sono dell'ordine dei microsecondi o meno. Dopo questa elaborazione, il router indirizza il pacchetto alla coda di uscita verso il router B.
Ritardo di attesa in coda
Nella coda, il pacchetto subisce un ritardo di attesa per la trasmissione sul link. La lunghezza del ritardo di accodamento di un pacchetto specifico dipenderà dal numero di pacchetti che sono arrivati in precedenza nella coda e sono ancora in attesa di trasmissione sul link. Se la coda è vuota e non si sta trasmettendo nessun altro pacchetto, allora il ritardo di attesa in coda del pacchetto sarà zero. D'altra parte, se il traffico è intenso e molti altri pacchetti entranti vengono inseriti in coda, il ritardo di attesa in coda si allunga. Il numero di pacchetti in coda che un pacchetto in arrivo potrebbe aspettarsi di trovare è una funzione dell'intensitè e della natura del traffico entrante. Il ritardo di accodamento può variare da pochi microsecondi a pochi millisecondi.
Ritardo di trasmissione
Supponendo che i pacchetti vengano prelevati dalla coda per essere trasmessi nell'ordine primo arrivato primo servito, come è comune nelle reti a commutazione di pacchetto, il pacchetto puó essere trasmesso solo dopo che tutti quelli che sono arrivati prima sono stati trasmessi. Sia L la lunghezza in bit del pacchetto, e si indichi la velocità di trasmissione del collegamento dal router A al router B con R bit/sec. Ad esempio, per un collegamento Ethernet a 10 Mbps, il tasso è R = 10 Mbps; mentre per un collegamento Ethernet a 100 Mbps, il tasso è R = 100 Mbps. Il ritardo di trasmissione è L/R. Questa è la quantità di tempo richiesta per trasmettere tutti i bit del pacchetto attraverso il canale. I ritardi di trasmissione sono tipicamente compresi nell'ordine dei microsecondi e i millisecondi.
Ritardo di propagazione
Dopo che un bit viene depositato sul canale, deve propagarsi al router B. Il tempo necessario per percorrere il cammino dall'inizio del canale fino a giungere al router B è il ritardo di propagazione. Il bit viaggia alla velocità di propagazione dell'energia sul canale. La velocità di propagazione dipende dal mezzo fisico (cioè, fibre ottiche, filo di rame twisted-pair, ecc.) ed è compresa nell'intervallo 2·108 m/s a 3·108 m/s, che è uguale o di poco inferiore, alla velocità della luce. Il ritardo di propagazione si ottiene dividendo la distanza tra due router per la velocità di propagazione del segnale sul canale. Cioè, il ritardo di propagazione è d/v, dove d è la distanza tra i Router A e B e v è la velocità di propagazione sul collegamento. Dopo che l'ultimo bit del pacchetto arriva al nodo B, questo e tutti i bit precedenti del pacchetto vengono memorizzati nel router B. Il processo prosegue con il router B che deve smistare il pacchetto. Nelle reti geografiche i ritardi di propagazione sono dell'ordine dei millisecondi.
Confronto tra il ritardo di Trasmissione e il ritardo di Propagazione
Il ritardo di trasmissione è la quantità di tempo necessaria al router per depositare tutti i bit del pacchetto sul canale; è una funzione della lunghezza del pacchetto e della velocità di trasmissione del canale, ma non ha niente a che fare con la distanza tra i due router. Il ritardo di propagazione, invece, è il tempo che impiega un bit per propagarsi da un router all'altro; è una funzione della distanza tra i due router, ma non ha nulla a che fare con la lunghezza del pacchetto o la velocità di trasmissione del collegamento.
Un'analogia potrebbe chiarire le nozioni di ritardo di trasmissione e di propagazione. Si consideri un'autostrada che ha un casello ogni 100 km, come mostrato nella Figura sotto. Si può pensare che i segmenti autostradali tra i caselli corrispondano ai collegamenti e i caselli corrispondano ai router. Per ipotesi le automobili viaggiano (cioè, si propagano) sulla strada ad una velocità di 100 km/ora (cioè, quando una macchina lascia un casello, accelera istantaneamente a 100 km/ora e mantiene tale velocità tra i caselli). Si supponga anche che 10 auto, che viaggiano insieme come una carovana, si susseguano in un ordine fisso. Si può pensare che ogni vettura sia un bit e la carovana sia un pacchetto. Si supponga anche che ogni casello autostradale per servire (cioè, trasmettere) una vettura impieghi 12 secondi, e che le auto della carovana siano le uniche auto in autostrada.

Infine, si supponga che quando la prima auto della carovana arriva ad un casello, attende finchè le altre nove vetture sono tutte arrivate e allineate dietro di essa. (Così l'intera carovana deve essere memorizzata al casello prima che possa cominciare la sua trasmissione). Il tempo necessario affinchè il casello faccia uscire l'intera carovana è (10 auto) / (5 auto / minuto) = 2 minuti. Questo tempo è analogo al ritardo di trasmissione in un router. Il tempo necessario richiesto ad una macchina per viaggiare dall'uscita di un casello all'altro casello è di 100 km / (100 km / ora) = 1 ora. Questo tempo è analogo al ritardo di propagazione. Pertanto, l'intervallo di tempo compreso da quando la carovana è memorizzata davanti al casello fino a quando è memorizzata davanti al casello successivo è la somma dei ritardi di trasmissione e di propagazione, in questo esempio, 62 minuti.
Che cosa accadrebbe se il tempo di servizio al casello di una carovana fosse superiore al tempo impiegato da una macchina per viaggiare tra i caselli? Per esempio, se le vetture viaggiano alla velocità di 1000 km/ora e il casello autostradale smaltisce le vetture al ritmo di una macchina per minuto, allora il tempo per percorrere la distanza tra due caselli è di 6 minuti e il tempo per servire una carovana è di 10 minuti. In questo caso, le prime vetture della carovana arriveranno al secondo casello prima che le ultime auto della carovana lascino il primo casello. Questa situazione si verifica anche nelle reti a commutazione di pacchetto - il primo bit di un pacchetto può arrivare ad un router, mentre molti dei rimanenti bit del pacchetto sono ancora in attesa di essere trasmessi dal router precedente.
Se si indicano con delab, dcoda, dtrasm, e dprop i ritardi di elaborazione, di accodamento, di trasmissione, e di propagazione, allora il ritardo totale in un nodo è:
dnodo = delab + dcoda + dtrasm + dprop
Questi ritardi possono variare notevolmente. Ad esempio, dprop può essere trascurabile (pochi microsecondi) per un collegamento che connette due router sullo stesso campus universitario; mentre dprop supera le centinaia di millisecondi tra due router interconnessi da un collegamento tramite un satellite geostazionario, anzi può essere il termine dominante in dnodo. Allo stesso modo, dtrasm potrebbe variare da quantità trascurabili a valori significativi. Il suo contributo è tipicamente trascurabile per velocità di trasmissione di 10 Mbps e superiori (per esempio, per le LAN); tuttavia, può essere di centinaia di millisecondi per grandi pacchetti inviati tramite Internet a bassa velocità che impiega il modem a 56Kbps. Il ritardo di elaborazione, delab, è spesso trascurabile; tuttavia, esso influenza fortemente la velocità massima di un router, che è la velocità massima alla quale un router può smistare i pacchetti.
Ritardo nella coda e perdita di pacchetti
La componente più complessa e interessante del ritardo in un nodo è il ritardo di attesa in coda, dcoda. In realtà, il ritardo di attesa in coda è molto importante e interessante per il computer networking. In questo paragrafo si propone solo una discussione intuitiva del ritardo di accodamento; il lettore più curioso può consultare un libro di statistica. A differenza degli altri tre ritardi (cioè, delab, dtrasm, e dprop), il ritardo di attesa in coda può variare da pacchetto a pacchetto. Ad esempio, se 10 pacchetti arrivano contemporaneamente in una coda vuota, il primo pacchetto trasmesso non subirà alcun ritardo nella coda, mentre l'ultimo pacchetto trasmesso subirà un ritardo di attesa in coda relativamente grande (per aspettare la conclusione della trasmissione degli altri nove pacchetti). Pertanto, per caratterizzare il ritardo di attesa in coda, si usano misure statistiche, come il ritardo medio di permanenza in coda, la varianza del ritardo di attesa, e la probabilità che il tempo di permanenza in coda superi un certo valore specificato.
Quand'è che il ritardo di attesa in coda si ritiene grande e quando insignificante? La risposta a questa domanda dipende dalla velocità con cui il traffico arriva nella coda, dalla velocità di trasmissione del canale, e dalla natura del traffico in arrivo, cioè, se i pacchetti arrivano a intervalli o arrivano a raffica. Per comprendere questo problema, si indichi con a il tasso medio con cui i pacchetti arrivano nella coda (a è espresso in unità di pacchetti/sec). R è la velocità di trasmissione; cioè, è la velocità (in bit/sec) alla quale i bit vengono prelevati dalla coda e depositati sul canale. Si ammetta anche, per semplicità, che tutti i pacchetti siano di L bit. Il tasso medio a cui i bit arrivano nella coda è L·a bit/sec. Infine, si supponga che la coda sia molto grande, in modo che possa contenere un numero infinito di bit. Il rapporto L·a/R, chiamato intensità di traffico, assume un ruolo importante nella valutazione dell'entità del ritardo di attesa in coda. Se L·a/R > 1, allora la velocità media alla quale i bit arrivano nella coda supera il tasso al quale i bit possono essere prelevati dalla coda. In questa situazione indesiderata, la coda tenderà ad aumentare senza limite e il ritardo di permanenza in coda tenderà all'infinito! Pertanto, il requisito fondamentale è: Progettare il sistema in modo che l'intensità del traffico non sia maggiore di 1.
Si consideri il caso L·a/R < 1. In questo caso, la natura del traffico in arrivo incide sul tempo di permanenza in coda. Ad esempio, se i pacchetti arrivano periodicamente, cioè, un pacchetto arriva ogni L/R secondi, allora ogni pacchetto arriverà in una coda vuota e non ci sarà alcun tempo di attesa. D'altra parte, se i pacchetti arrivano a raffica ma periodicamente, ci può essere un significativo ritardo medio di attesa in coda. Ad esempio, si supponga che N pacchetti arrivino contemporaneamente ogni (L/R)·N secondi. Allora il primo pacchetto trasmesso non subisce il ritardo nella coda; il secondo pacchetto trasmesso resta L/R secondi nella coda; e più in generale, l'n-esimo pacchetto trasmesso subisce un ritardo in coda di (n - 1)·L/R secondi. Come esercizio si calcoli il tempo di permanenza medio.
Tipicamente, il processo di arrivo in una coda è casuale; cioè, gli arrivi non seguono un modello deterministico e i pacchetti sono distanziati da quantità di tempo casuali. In un caso più realistico, la quantità L·a/R non è sufficiente a caratterizzare completamente le statistiche del ritardo in coda. Tuttavia, è utile per ottenere una comprensione intuitiva della misura del tempo di permanenza in coda. In particolare, se l'intensità del traffico è vicina a zero, allora gli arrivi dei pacchetti sono pochi e distanti tra loro ed è improbabile che un pacchetto in arrivo troverà un altro pacchetto nella coda. Quindi, il ritardo medio dovuto all'attesa in coda sarà prossimo a zero. D'altra parte, quando l'intensità del traffico è vicina a 1, ci saranno intervalli di tempo in cui il tasso di arrivo supera la capacità di trasmissione (dovuta a variazioni del tasso di arrivo dei pacchetti) e, durante questi periodi, si formerà una coda; quando il tasso di arrivo è inferiore alla capacità di trasmissione, la lunghezza della coda si ridurrà. Tuttavia, come l'intensità del traffico si avvicina 1, la lunghezza media della coda diventa sempre più grande. La dipendenza qualitativa del tempo medio di attesa in coda dall'intensità del traffico è illustrato nella Figura.
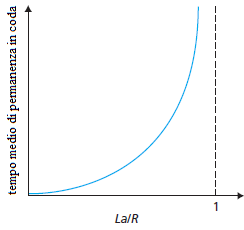
Un aspetto importante da osservare nella figura è il fatto che quando l'intensità del traffico si avvicina a 1, il ritardo medio di attesa in coda aumenta rapidamente. Un piccolo aumento percentuale dell'intensità si tradurrà in un incremento percentuale molto più grande del ritardo. Questo fenomeno si osserva anche nella circolazione dei veicoli in città. Se si guida a bassa velocità su una strada congestionata, significa che l'intensità del traffico è prossima a 1. Se qualche evento provoca una quantità di traffico leggermente più grande del solito, i ritardi che si verificano possono essere enormi.
Perdita di pacchetti
Nella discussione precedente, si è assunto che la coda è in grado di contenere un numero infinito di pacchetti. In realtà una coda che precede un collegamento ha capacità finita, anche se la sua dimensione dipende dalla progettazione del router e dal costo. Poichè la capacità della coda è finita, i ritardi dei pacchetti non crescono all'infinito mentre l'intensità del traffico si avvicina a 1. Invece, un pacchetto in arrivo può trovare la coda piena. Non avendo posto per memorizzare un tale pacchetto, un router scarterà quel pacchetto; cioè il pacchetto sarà perso.
La frazione di pacchetti persi aumenta all'aumentare dell'intensità del traffico. Pertanto, le prestazioni in un nodo sono misurate non solo in termini di ritardo, ma anche in termini di probabilità di perdita di pacchetti. Il protocollo di livello 4 può riconoscere la perdita di un pacchetto e provvedere a ritrasmetterlo per garantire che tutti i dati vengono poi trasferiti dalla sorgente alla destinazione.
Ritardo End-to-End
La discussione fino a questo punto si è concentrata sul ritardo in un nodo, cioè il ritardo in un singolo router. Si consideri ora il ritardo totale dalla sorgente alla destinazione. Per illustrare questo concetto, si supponga che ci siano N-1 router tra l'host sorgente e l'host di destinazione, e anche, per il momento, che la rete non è congestionata (in modo che i tempi di attesa in coda siano trascurabili), il ritardo di elaborazione in ogni router e nell'host di origine è delab, la velocità di trasmissione è R bit/sec, e il tempo di propagazione su ciascun collegamento è dprop. I ritardi nei nodi si accumulano e danno un ritardo end-to-end:
dend-end = N · (delab + dtrasm + dprop)
nella quale, ancora una volta, dtrasm = L/R, dove L è la dimensione del pacchetto. Si noti che questa equazione è una generalizzazione dell'equazione precedente, che non tiene conto dei ritardi di elaborazione e di propagazione. Si lascia al lettore la generalizzazione di questa equazione al caso di ritardi eterogenei nei nodi e la presenza di un ritardo di attesa medio in coda ad ogni nodo.
Traceroute
Per avere un'idea del ritardo end-to-end in una rete di computer, si può usare il programma Traceroute. Traceroute è un semplice programma che può essere eseguito in qualsiasi host Internet. Quando l'utente specifica un nome host di destinazione, il programma nell'host di origine invia più pacchetti speciali verso quella destinazione. Poichè questi pacchetti fanno strada verso la destinazione, passano attraverso una serie di router. Quando un router riceve uno di questi pacchetti speciali, rimanda alla fonte un breve messaggio che contiene il nome e l'indirizzo del router.
Più precisamente: ci siano N-1 router tra la sorgente e la destinazione. La sorgente invierà N pacchetti speciali nella rete, indirizzati alla destinazione finale. Questi N pacchetti speciali sono numerati da 1, il primo, a N, l'ultimo. Quando l'n-mo router riceve l'n-mo pacchetto segnato n, il router non inoltra il pacchetto verso la sua destinazione, ma restituisce un messaggio alla sorgente. Quando l'host di destinazione riceve il pacchetto N, restituisce un altro messaggio di ritorno alla sorgente. La sorgente registra il tempo che intercorre tra quando invia un pacchetto e quando riceve il messaggio di ritorno corrispondente; registra anche il nome e l'indirizzo del router (o l'host di destinazione), che restituisce il messaggio. In questo modo, la sorgente può ricostruire il percorso intrapreso dai pacchetti che viaggiano dalla sorgente alla destinazione, e la sorgente è in grado di determinare i tempi di andata e ritorno per tutti i router intermedi. Traceroute ripete il processo appena descritto tre volte, quindi la sorgente invia effettivamente 3·N pacchetti alla destinazione. RFC 1393 descrive Traceroute in dettaglio.
Ecco un esempio di output del programma Traceroute, dove il percorso era stato tracciato dall'host di origine (presso l'Università del Massachusetts) gaia.cs.umass.edu al cis.poly.edu host (presso il Politecnico di Brooklyn). L'uscita ha sei colonne: la prima colonna è il numero n, cioè il numero del router lungo il percorso; la seconda colonna è il nome del router; la terza colonna è l'indirizzo del router (di forma xxx.xxx.xxx.xxx); le ultime tre colonne sono i ritardi di andata e ritorno per i tre invii. Se la sorgente non riceve almeno tre messaggi da ciascun router (a causa della perdita di pacchetti in rete), Traceroute pone un asterisco subito dopo il numero di router e segnala meno di tre volte di andata e ritorno per quel router.
1 cs-gw (128.119.240.254) 1.009 ms 0.899 ms 0.993 ms 2 128.119.3.154 (128.119.3.154) 0.931 ms 0.441 ms 0.651 ms 3 border4-rt-gi-1-3.gw.umass.edu (128.119.2.194) 1.032 ms 0.484 ms 0.451 ms 4 acr1-ge-2-1-0.Boston.cw.net (208.172.51.129) 10.006 ms 8.150 ms 8.460 ms 5 agr4-loopback.NewYork.cw.net (206.24.194.104) 12.272 ms 14.344 ms 13.267 ms 6 acr2-loopback.NewYork.cw.net (206.24.194.62) 13.225 ms 12.292 ms 12.148 ms 7 pos10-2.core2.NewYork1.Level3.net (209.244.160.133) 12.218ms 11.823ms 11.793ms 8 gige9-1-52.hsipaccess1.NewYork1.Level3.net (64.159.17.39) 13.0ms 11.5ms 13.2ms 9 p0-0.polyu.bbnplanet.net (4.25.109.122) 12.716 ms 13.052 ms 12.786 ms 10 cis.poly.edu (128.238.32.126) 14.080 ms 13.035 ms 12.802 ms
Nella traccia precedente ci sono nove router tra la sorgente e la destinazione. La maggior parte di questi router hanno un nome, e tutti hanno un indirizzo. Ad esempio, il nome del Router 3 è border4-rt-gi-1-3.gw.umass.edu e il suo indirizzo è 128.119.2.194. Guardando i dati forniti da questo router, si vede che nella prima delle tre prove il ritardo di trasmissione tra la sorgente e il router era 1,03 msec. I ritardi di andata e ritorno per le successive due prove erano 0.48 e 0.45 msec. Questi ritardi andata e ritorno comprendono tutti i ritardi appena discussi, tra cui ritardi di trasmissione, ritardi di propagazione, ritardi di elaborazione nel router, e ritardi di attesa in coda. Poichè il ritardo subito nella coda è variabile nel tempo, il ritardo di trasmissione del pacchetto n inviato a un router n volte può essere più lungo del ritardo di trasmissione del pacchetto n+1 inviato al router n+1. Infatti, si osserva questo fenomeno nell'esempio precedente: i ritardi al router 6 sono più grandi dei ritardi al router 7.
Visitare http://www.traceroute.org, che fornisce un'interfaccia Web per un ampio elenco di siti da tracciare. Si sceglie una sorgente e si fornire il nome host per qualsiasi destinazione. Il programma traceroute poi fa tutto il lavoro. Ci sono una serie di software liberi che forniscono un'interfaccia grafica per Traceroute; ad esempio PingPlotter.
Sistema terminale, Applicazioni e altri ritardi
Oltre ai ritardi di elaborazione, trasmissione e propagazione, ci possono essere ulteriori ritardi significativi nei sistemi terminali. Ad esempio, un sistema terminale che vuole trasmettere un pacchetto in un mezzo condiviso (ad esempio, come in un WiFi o un modem via cavo) può ritardare volutamente la sua trasmissione come parte del suo protocollo di condivisione del mezzo con altri sistemi terminali. Un'altro ritardo importante è il ritardo di impacchettamento, che è presente nelle applicazioni Voiceover-IP (VoIP). In VoIP, il lato trasmittente deve prima riempire un pacchetto con la codifica vocale digitalizzata prima di passare il pacchetto a Internet. Questo tempo per riempire un pacchetto può essere significativo e l'utente percepisce una bassa qualità della chiamata VoIP.
Flusso in una rete di calcolatori
Oltre ai ritardi e alla perdita di pacchetti, un altro parametro di prestazione delle reti di computer è il throughput end-to-end. Per definire il flusso, si pensi di trasferire un file di grandi dimensioni dall'host A all'host B attraverso una rete di computer. Tale trasferimento potrebbe riguardare, per esempio, un grande file video da un peer all'altro in un sistema p2p. La velocità istantanea, in qualsiasi istante di tempo, è il tasso (in bit/sec) a cui l'host B riceve il file. (molte applicazioni, tra cui molti sistemi di condivisione di file P2P, visualizzano la velocità istantanea durante il download nella interfaccia utente). Se il file è composto da F bit e il trasferimento avviene in T secondi, la velocità media del trasferimento del file é F/T bit/sec. Per alcune applicazioni, come la telefonia su Internet, è auspicabile avere un basso ritardo e una velocità istantanea costantemente al di sopra una certa soglia (per esempio, più di 24 kbps per alcune applicazioni di telefonia Internet e più di 256 kbps per alcune applicazioni video in tempo reale). Per altre applicazioni, comprese quelle relative al trasferimento di file, il ritardo non è critico, ma è desiderabile avere la massima velocità possibile.
Per illustrare il concetto di flusso, si considerino alcuni esempi.
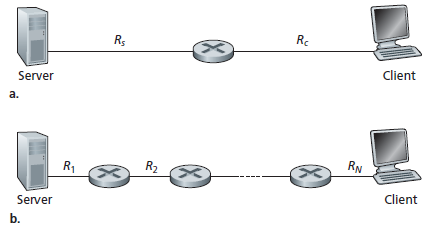
La figura (a) mostra due sistemi terminali, un server e un client, collegati da due canali di comunicazione e un router. Si consideri il flusso per un trasferimento di file dal server al client. Si indichi con Rs la velocità del collegamento tra il server e il router; e con Rc si indichi la velocità del collegamento tra il router e il client. Si supponga che gli unici bit inviati nell'intera rete sono quelli dal server al client. Ci si chiede, in questo scenario ideale, qual è il flusso tra il server e il client. Per rispondere a questa domanda, si pensi che i bit rappresentino un fluido e il canale di comunicazione rappresenti i tubi. Chiaramente, il server non riesce a pompare i bit attraverso il suo collegamento ad un ritmo più veloce di Rs bps; e il router non può inoltrare i bit a un ritmo più veloce di Rc bps. Se Rs<Rc, i bit fluiranno dal server attraverso il router e giungeranno al client a un tasso di Rs bps, dando un throughput di Rs bps.
Se, d'altra parte, Rc<Rs, allora il router non sarà in grado di trasmettere i bit più rapidamente di quanto li riceve. In questo caso, i bit lasceranno il router al tasso Rc, dando un flusso end-to-end di Rc. (Notare anche che se i bit continuano ad arrivare al router a velocità Rs, e continuano a lasciare il router a velocità Rc, nel router si forma la coda di bit in attesa di trasmissione al client che continuerà a crescere). Così, per questa semplice rete a due canali, il flusso è min{Rc, Rs}, cioè, è una velocità di trasmissione del collegamento detta"collo di bottiglia". Avendo determinato il throughput, si può calcolare, con approssimazione, il tempo necessario per trasferire un file di F bit dal server al client come F/min{Rs, Rc}. Numericamente, si supponga che si sta scaricando un file MP3 di F = 32 milioni di bit, il server ha una velocità di trasmissione Rs = 2 Mbps, e si dispone di un canale con velocità Rc = 1 Mbps. Il tempo necessario per trasferire il file è quindi 32 secondi. Naturalmente, queste espressioni per la velocità e il tempo di trasferimento sono solo approssimative, in quanto non tengono conto dei ritardi store-and-forward, di elaborazione, e altre problematiche legate ai protocolli.
La figura (b) mostra una rete con N canali tra il server e il client, in cui le velocità di trasmissione dei canali sono R1, R2, ..., RN. Applicando la stessa analisi per la rete con due canali, si trova che la velocità di trasferimento di un file dal server al client è min {R1, R2, ..., RN}, che è ancora una volta la velocità di trasmissione del collegamento che rappresenta il collo di bottiglia lungo il percorso tra server e client.
Si consideri un altro esempio. La figura (a) mostra due sistemi terminali, un server e un client, collegati ad una rete di computer. Si calcoli il flusso per un trasferimento di file dal server al client. Il server è collegato alla rete con un canale di capacità Rs e il client è connesso alla rete con un canale di capacità Rc. Si ammetta che tutti i canali nel nucleo della rete di comunicazione hanno velocità di trasmissione molto elevata, molto più alta di Rs e Rc. Infatti, oggi, il nucleo di Internet è dotato di canali ad alta velocità per cui difficilmente si verifica la congestione. Inoltre si suppone che gli unici bit inviati nell'intera rete sono quelli dal server al client. Poichè il nucleo della rete di computer è come un vasto tubo, in questo esempio, il tasso al quale i bit possono fluire dalla sorgente alla destinazione è nuovamente il minimo tra Rs e Rc, cioè, il throughput = min{Rs, Rc}. Pertanto, il fattore limitante del throughput in Internet di oggi è tipicamente la velocità nel punto di accesso.
Come ultimo esempio, si consideri la parte (b) figura seguente in cui ci sono 10 server e 10 client connessi alla rete di telecomunicazioni.
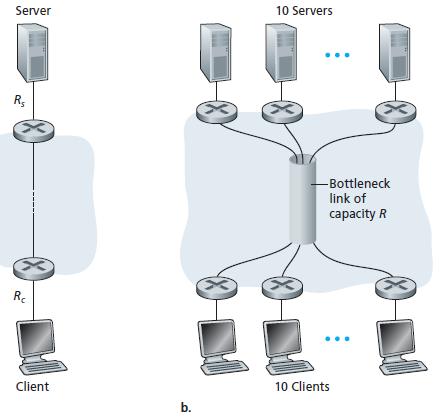
In questo esempio, ci sono 10 download simultanei in corso, che coinvolgono 10 coppie di client-server. Per ipotesi, questi 10 download sono l'unico traffico nella rete al momento attuale. Come mostrato nella figura, vi è un canale nella rete che è attraversato da tutti i 10 download. Sia R la velocità di trasmissione di questo canale. Si ammetta che tutti i link di accesso ai server hanno la stessa capacità Rs, tutti i link di accesso ai client hanno la stessa capacità Rc, e le velocità di trasmissione di tutti i canali nella rete, tranne quello comune che ha capacità R, sono molto più elevate di Rs, Rc, e R. Ci si chiede, quali sono i throughput dei download? Chiaramente, se la capacità del canale comune, R, è cento volte più grande di Rs e Rc allora il throughput per ogni download sarà nuovamente min{Rs, Rc}. Ma cosa succede se il tasso del canale comune è dello stesso ordine di Rs e Rc? Quale sarà la velocità in questo caso? Si esamini un esempio numerico. Sia Rs = 2 Mbps, Rc = 1 Mbps, R = 5 Mbps. Il canale comune divide la sua velocità di trasmissione in parti uguali tra i 10 download. Poi il collo di bottiglia per ogni download non è più nel punto di accesso, ma è invece il canale condiviso nella rete, che assegna soltanto 500 kbps di velocità ad ogni download. Così il throughput end-to-end per ogni download è ridotto a 500 kbps. Gli esempi nelle figure precedenti, mostrano che la velocità dipende dalle velocità di trasmissione dei canali attraversati dai dati. Si è visto che quando non c'è altro traffico, la velocità può semplicemente essere approssimata alla velocità del canale più lento lungo il percorso tra sorgente e destinazione. L'esempio di figura (b) mostra che più in generale il throughput dipende non solo dalla velocità di trasmissione dei canali lungo il percorso, ma anche dal traffico. In particolare, un collegamento con un alto tasso di trasmissione può comunque essere il collegamento collo di bottiglia per un trasferimento di file se molti altri flussi di dati passano attraverso quel collegamento.