Algoritmi di instradamento: Distance Vector.
ALGORITMI DI INSTRADAMENTO
La scelta di un algoritmo di instradamento è difficile, in quanto esistono più criteri di ottimalità spesso contrastanti, ad esempio minimizzare il ritardo medio di ogni pacchetto o massimizzare l'utilizzo delle linee.
Occorre che la scelta sia preceduta dalla definizione di criteri misurabili. Occorre cioè introdurre dei parametri metrologici in base ai quali misurare le caratteristiche di un cammino per scegliere, ad esempio, il migliore tra due cammini alternativi. Gli unici due parametri universalmente accettati sono:
il numero di salti effettuati (hop), cioè il numero di Router attraversati lungo un cammino;
il costo, cioè la somma dei costi di tutte le linee attraversate lungo un cammino.
Entrambi questi parametri sono di demerito, in quanto il costo di una linea è assegnato in modo inversamente proporzionale alla velocità della linea stessa, e gli hop indicano router attraversati e quindi ritardi introdotti.
Metriche che tengano in considerazione il carico della rete sono più difficili da mettere a punto, in quanto portano facilmente a situazioni di routing instabile. Le tecniche più moderne consentono al più di operare un load splitting (bilanciamento del traffico) tra cammini paralleli, eventualmente attivando circuiti commutati, quali quelli forniti dalla rete ISDN in presenza di un guasto (ad esempio, funzionalità di backup di un CDN) o per gestire un eccesso di traffico su di un link (traffico di trabocco).
La scelta dell'algoritmo di instradamento ottimale è anche complicata dalle limitate risorse di memoria e CPU disponibili oggi sui router, specialmente se confrontate con la complessità delle reti ed in particolare con l'elevato numero di nodi collegabili con una topologia qualsiasi. Algoritmi troppo complessi, operanti su reti molto grandi, potrebbero richiedere tempi di calcolo inaccettabili.
Riassumendo, le caratteristiche che in generale si richiedono ad un algoritmo di routing sono:
semplicità dell'algoritmo, poichè i router hanno CPU e memoria finite e devono impiegare la maggior parte del loro tempo a instradare pacchetti, non a calcolare nuove tabelle di instradamento;
robustezza e adattabilità alle variazioni di topologia; non deve esistere nessun presupposto nè vincolo sulla topologia di rete, che deve poter essere modificata dinamicamente senza interrompere il funzionamento della rete;
ottimalità nella scelta dei cammini, rispetto soprattutto ai due criteri elencati precedentemente;.
stabilità: a fronte di una rete stabile l'algoritmo deve sempre convergere velocemente ad un instradamento stabile, cioè non deve modificare le tabelle di instradamento se non a fronte di una variazione di topologia;
equità: nessun nodo deve essere privilegiato o danneggiato.
Gli algoritmi di routing si dividono in due gruppi: non adattativi (statici e deterministici) e adattativi (dinamici e non deterministici). I primi utilizzano criteri fissi di instradamento, mentre gli altri calcolano le tabelle di instradamento in funzione della topologia della rete e dello stato dei link.
Sono algoritmi del primo gruppo il fixed directory routing e il flooding, mentre appartengono al secondo gruppo il routing centralizzato, il routing isolato e il routing distribuito.
Entrambi i gruppi hanno la loro ragione di esistere, in zone diverse della rete. Infatti, se per sfruttare al meglio le magliature della rete è indispensabile avere algoritmi di routing dinamico, nelle zone più periferiche della rete con topologia ad albero, cioè con un solo cammino che le interconnette al resto della rete, un routing statico può risultare più semplice e non presentare svantaggi.
Gli algoritmi di più moderna concezione sono quelli distribuiti, che si suddividono ulteriormente in due famiglie: distance vector e link state packet.
ALGORITMI STATICI
Fixed directory routing
Il fixed directory routing prevede che ogni nodo abbia una tabella di instradamento che metta in corrispondenza il nodo da raggiungere con la linea da usare, e che tale tabella sia scritta manualmente dal gestore della rete nel router tramite un'operazione di management.
Il gestore ha il totale controllo dei flussi di traffico sulla rete, ma è necessario un suo intervento manuale per il reinstradamento di detti flussi in presenza di guasti. Questo approccio è spesso utilizzato in TCP/IP per le parti non magliate della rete e le regole di instradamento specificate su ogni singolo router prendono il nome di route statiche.
Esiste una variante, detta quasi-statica, che adotta tabelle con più alternative da scegliere secondo un certo ordine di priorità, in funzione dello stato della rete. Questo approccio, che consente di avere cammini alternativi in caso di guasto, è adottato, ad esempio, dalla rete SNA.
Occorre comunque evidenziare che la gestione manuale delle tabelle risulta molto complessa e difficoltosa, soprattutto per reti di grandi dimensioni.
Flooding
Il flooding è un altro algoritmo non adattativo, in cui ciascun pacchetto in arrivo viene ritrasmesso su tutte le linee, eccetto quella su cui è stato ricevuto.
Concepito per reti militari a prova di sabotaggio, se realizzato nel modo sopra descritto massimizza la probabilità che il pacchetto arrivi a destinazione, ma introduce un carico elevatissimo sulla rete.
Si può cercare di ridurre il carico utilizzando tecniche di selective flooding, in cui i pacchetti vengono ritrasmessi solo su linee selezionate.
Un primo esempio, senza applicazioni pratiche, è l'algoritmo random walk che sceglie in modo pseudo-casuale su quali linee ritrasmettere il pacchetto.
Una miglioria più efficace si ha scartando i pacchetti troppo vecchi, cioè quelli che hanno attraversato molti router: a tal scopo nell'header del pacchetto viene inserito un age-counter.
Un'ultima miglioria, ancora più significativa, consiste nello scartare un pacchetto la seconda volta che passa in un nodo: in tal modo si realizza una tecnica per trasmettere efficientemente la stessa informazione a tutti i nodi, qualsiasi sia la topologia. Lo svantaggio è che bisogna memorizzare tutti i pacchetti su ogni nodo per poter verificare se sono già passati.
ALGORITMI ADATTATIVI
Gli algoritmi di instradamento adattativi sono quelli in cui le tabelle dipendono dalle informazioni raccolte sulla topologia della rete, sul costo dei cammini e sullo stato degli elementi che la compongono. Gli algoritmi adattativi possono essere centralizzati (in un unico punto della rete vengono raccolte e analizzate tutte le informazioni, e calcolate le tabelle), isolati (ogni router è indipendente dagli altri) o distribuiti (i router cooperano al calcolo delle tabelle).
Routing centralizzato
Il routing centralizzato è tra i metodi adattativi quello che più si avvicina al fixed directory routing. Presuppone l'esistenza di un RCC (Routing Control Center) che conosce la topologia della rete, riceve da tutti i nodi informazione sul loro stato e su quello dei collegamenti, calcola le tabelle di instradamento e le distribuisce.
È un metodo che consente una gestione della rete molto accurata, in quanto permette di calcolare le tabelle anche con algoritmi molto sofisticati, ma implica l'esistenza di un unico gestore, ipotesi questa oggi molto spesso non realistica.
Il RCC, per ragioni di affidabilità, deve essere duplicato e la porzione di rete intorno ad esso è soggetta ad un elevato volume di traffico di servizio: informazioni di stato che arrivano al RCC e tabelle di instradamento che escono dal RCC.
In caso di guasti gravi possono verificarsi situazioni in cui il RCC perde il contatto con una parte periferica della rete e si verificano quindi degli aggiornamenti parziali di tabelle che possono determinare situazioni di loop.
Questo metodo è usato con successo nella rete TymNet, che è un'importante rete X.25 internazionale.
Routing isolato
Il routing isolato è l'opposto di quello centralizzato, visto che non solo non esiste un RCC, ma ogni router calcola in modo indipendente le tabelle di instradamento senza scambiare informazioni con gli altri router.
Esistono due algoritmi di routing isolato riportati in letteratura: hot potato e backward learning.
Il primo è famoso solo per il suo nome (hot potato). Ogni router considera un pacchetto ricevuto come una patata bollente e cerca di liberarsene nel minor tempo possibile, ritrasmettendo il pacchetto sulla linea con la coda di trasmissione più breve.
Il metodo di backward learning è invece utilizzato per calcolare le tabelle di instradamento nei bridge conformi allo standard IEEE 802.1D. Il router acquisisce una conoscenza indiretta della rete analizzando il traffico che lo attraversa: se riceve un pacchetto proveniente dal nodo A sulla linea L3, il backward learning impara che A è raggiungibile attraverso la linea L3.
È possibile migliorare il backward learning inserendo nell'header del pacchetto un campo di costo inizializzato a zero dalla stazione mittente ed incrementato ad ogni attraversamento di un router. In tale modo i router possono mantenere più alternative per ogni destinazione, ordinate per costo crescente.
Un router mantiene due alternative (entry) per ogni destinazione nella tabella di instradamento. Quando da una sorgente giunge un pacchetto con costo minore di quello memorizzato, la riga relativa a quella sorgente viene aggiornata in quanto si è scoperto un cammino più conveniente di uno già noto.
Il limite di questo metodo consiste nel fatto che i router imparano solo le migliorie e non i peggioramenti nello stato della rete: infatti se cade un link e si interrompe un cammino, semplicemente non arrivano più pacchetti da quel cammino, ma non giunge al router nessuna informazione che il cammino non è più disponibile.
Per tale ragione occorre limitare temporalmente la validità delle informazioni presenti nelle tabelle di instradamento: ad ogni entry viene associata una validità temporale che viene inizializzata ad un dato valore ogni volta che un pacchetto in transito conferma l'entry, e decrementata automaticamente con il passare del tempo.
Quando la validità temporale di un'entry giunge a zero, questa viene invalidata ed eliminata dalla tabella di instradamento.
Qualora ad un router giunga un pacchetto per una destinazione ignota, il router ne fa il flooding.
Il backward learning può generare loop su topologie magliate, per cui, ad esempio nei bridge, lo si integra con l'algoritmo di spanning tree per ridurre la topologia magliata ad un albero.
Routing distribuito
Il routing distribuito è indubbiamente quello di maggior interesse per la soluzione dei problemi di internetworking. Esso si pone come una scelta di compromesso tra i due precedenti: non esiste un RCC, ma le sue funzionalità sono realizzate in modo distribuito da tutti i router della rete, che a tale scopo usano un protocollo di servizio per scambiare informazioni tra loro ed un secondo protocollo di servizio per scambiare informazioni con i sistemi terminali. Tali protocolli vengono detti di servizio in quanto non veicolano dati di utente, che sono gestiti da un terzo protocollo, ma solo informazioni utili al calcolo delle tabelle di instradamento e al neighbor greetings.
Le tabelle di instradamento vengono calcolate a partire dai due parametri di ottimalità precedentemente descritti: costo e hop. Il costo di ciascuna linea di ciascun router è un parametro che viene impostato dal network manager tramite il software di gestione dei router stessi.
Gli algoritmi di routing distribuito sono oggi adottati da DECnet, TCP/IP, OSI, APPN, ecc., e si suddividono ulteriormente in due famiglie: algoritmi distance vector e algoritmi link state packet.
ALGORITMI DI ROUTING DISTANCE VECTOR
L'algoritmo distance vector è anche noto come algoritmo di Bellman-Ford. Per realizzare tale algoritmo ogni router mantiene, oltre alla tabella di instradamento, una struttura dati, detta distance vector per ogni linea. Il distance vector associato a ciascuna linea contiene informazioni ricavate dalla tabella di instradamento del router collegato all'altro estremo della linea.
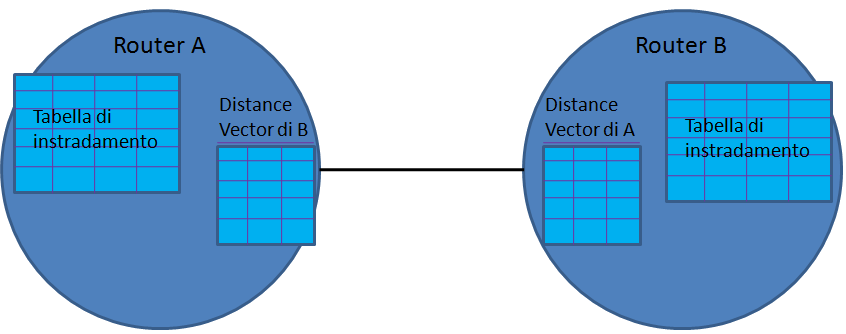
Il calcolo delle tabelle di instradamento avviene tramite un processo di fusione (merge) di tutti i distance vector associati alle linee attive di un router. Tutte le volte che un router calcola una nuova tabella di instradamento, la invia agli IS adiacenti sotto forma di distance vector.
La tabella di instradamento è un insieme di quadruplette {indirizzo, hop, costo, linea} che contiene per ogni nodo della rete (indirizzo), sia esso un router o un sistema terminale, l'informazione relativa al cammino migliore per raggiungere tale nodo in termini di numero di router da attraversare (hop), somma dei costi delle linee da attraversare (costo) e linea su cui ritrasmettere il messaggio (linea).
Ciascun router apprende tramite un protocollo di neighbor greetings le informazioni relative ai nodi adiacenti, siano essi router o sistemi terminali, e le inserisce nella tabella di instradamento. Quando un router modifica la sua tabella di instradamento per una delle ragioni descritte nel seguito, esso invia a tutti i router adiacenti, cioè collegati da un cammino fisico diretto (solo a quelli adiacenti, non a tutti i router della rete) il suo distance vector che ricava dalle prime tre colonne della sua tabella di instradamento e che risulta quindi un insieme di triplette del tipo {indirizzo, hop, costo}.
Quando un router riceve un distance vector da un router adiacente, prima di memorizzarlo, somma uno a tutti i campi hop e il costo della linea da cui ha ricevuto il distance vector a tutti i campi costo.
Quando un router memorizza un distance vector nella sua struttura dati locale, verifica se sono presenti variazioni rispetto al distance vector precedentemente memorizzato: in caso affermativo ricalcola le tabelle di instradamento fondendo (merge) tutti i distance vector delle linee attive. Analoga operazione di ricalcolo avviene quando una linea passa dallo stato ON allo stato OFF o viceversa. Molte implementazioni ricalcolano anche le tabelle di instradamento periodicamente.
La fusione avviene secondo il criterio di convenienza del costo: a parità di costo secondo il minimo numero di hop e a parità di hop con scelta casuale. In figura 11 è riportato un esempio di calcolo della tabella di instradamento. La linea L0 indica il router stesso.
Se la tabella di instradamento risulta variata rispetto alla precedente, il distance vector relativo viene inviato ai router adiacenti. Alcune implementazioni di protocolli distance vector inviano anche i distance vector periodicamente, ad esempio il RIP invia il distance vector ogni 30 secondi.
La modalità operativa descritta crea un fenomeno simile a quello di una pietra che cade in un catino di acqua. La pietra è una variazione dello stato della rete, il catino è la rete, le onde generate dalla caduta della pietra sono i distance vector che si dipartono dal luogo di impatto, arrivano ai bordi della rete, si specchiano e tornano verso il centro e ancora verso la periferia e poi verso il centro, con un moto che si ripete più volte prima di giungere a stabilità.
Il vantaggio di questo algoritmo è la facilità di implementazione. Gli svantaggi sono:
la complessità elevata. Questo rende improponibile l'utilizzo di tale algoritmo per reti con più di 1000 nodi, a meno che non venga adottato un partizionamento gerarchico
la lenta convergenza ad un istradamento stabile. Infatti l'algoritmo converge con una velocità proporzionale a quella del link più lento e del router più lento presenti nella rete;
la difficoltà di capirne e prevederne il comportamento su reti grandi, poichè nessun nodo ha la mappa della rete.
Questo algoritmo è usato in DECnet fase IV e in alcune realizzazioni TCP/IP (protocolli RIP e IGRP).
Esempio
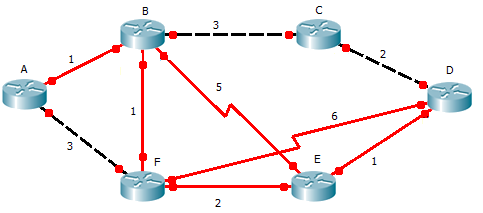
Nella seguente rete, si consideri il router A
-
Ipotizzando che il router A conosca solo i propri vicini, la sua tabella di instradamento è
Destinazione Costo Hop Next Hop A 0 0 - - B 1 1 B F 3 1 F -
I router B ed F inviano i propri distance vector ad A
Destinazione Costo Hop Destinazione Costo Hop A 1 1 A 3 1 B - - - - B 1 1 C 3 1 D 6 1 E 5 1 E 2 1 F 1 1 F - - - - Distance Vector inviato da B ad A Distance Vector inviato da F ad A Il router A, prima di memorizzare i distance vector ricevuti, somma 1 a tutti i campi Hop e aggiunge il costo della linea da cui ha ricevuto il distance vector a tutti campi costo. Inoltre, il router confronta il nuovo distance vector ottenuto con quello precedente e, se trova differenze, ricalcola la tabella di instradamento.
La nuova tabella di instradamento del router A, ottenuta dalla fusione dei distance vector con le righe già presenti nella tabella di instradamento è:
Destinazione Costo Hop Next Hop A 0 0 - - Si trattiene la riga della tabella di instradamento di A B 1 1 B Si trattiene la riga della tabella di instradamento di A C 4 2 B 4 = costo da A a B (1) + costo contenuto nel distance vector ricevuto da B (3) D 9 2 F 9 = costo da A a F (3) + costo contenuto nel distance vector ricevuto da F (6) E 5 2 F 5 = costo da A a F (3) + costo contenuto nel distance vector ricevuto da F (2) F 2 2 B Si sceglie di raggiungere F attraverso B Tabella di instradamento del router A
Il router C invia il proprio Distance Vector a B:
Destinazione Costo Hop Destinazione Costo Hop B 3 1 B 6 2 C 0 0 C 3 1 D 2 1 D 5 2 Distance Vector inviato da C a B Distance Vector memorizzato da B Il router E invia il suo distance vector ad F
Destinazione Costo Hop Destinazione Costo Hop B 5 1 B 7 2 D 1 1 +2 (costo della linea tra E ed F) D 3 2 E - - - - E 2 1 F 2 1 F 4 2 Distance Vector inviato da E a F Distance Vector memorizzato da F I router B ed F ricalcolano le proprie tabelle di instradamento fondendo la tabella di instradamento con i distance vector ricevuti.
Destinazione Costo Hop Next hop Destinazione Costo Hop Next hop A 1 1 A A 3 1 A B 0 0 - - B 1 1 B C 3 1 C - - ? ? ? D 5 2 C D 3 2 E E 5 1 E E 2 1 E F 1 1 F F 0 0 - - Tabella di instradamento di B Tabella di instradamento di F Si noti che il router F non conosce ancora la presenza del router C, pertanto, nella sua tabella di instradamento non ha la riga verso quella destinazione.
Dopo aver ricalcolato le proprie tabelle di instradamento, i due router inviano i loro distance vector al router A, Il quale ricalcola la propria tabella di instradamento:
Destinazione Costo Hop Next Hop A 0 0 - - B 1 1 B C 4 2 B D 6 3 F E 4 3 B F 2 2 B Tabella di instradamento del router A
Il router F invia il suo distance vector a B. Il router B si accorge che D è raggiungibile attraverso un percorso di costo minore. Ricalcola la propria tabella di instradamento e comunica ad A il suo distance vector. Il router A ricalcola la tabella di instradamento:
Destinazione Costo Hop Next Hop A 0 0 - - B 1 1 B C 4 2 B D 5 4 B E 4 3 B F 2 2 B Tabella di instradamento del router A