Routing in Internet.
Routing gerarchico
Si potrebbe pensare che, nella rete, i router eseguano lo stesso algoritmo di instradamento, per calcolare i percorsi di costo minimo tra due qualsiasi nodi dell'intera rete. È un'ipotesi non realistica per due motivi:
Estensione geografica. Quando il numero dei router diventa molto grande, le operazioni di calcolo, memorizzazione e trasmissione delle informazioni di instradamento incidono in modo proibitivo sulle prestazioni globali della rete. Nella rete Internet ci sono centinaia di milioni di host. Se si dovessero memorizzare tutte le informazioni per ciascuno di questi, sarebbe necessaria una memoria enorme. Per trasmettere i messaggi di aggiornamento, non resterebbe banda per trasmettere i pacchetti degli utenti. L'algoritmo Distance Vector potrebbe anche non riuscire a convergere ad uno stato stabile.
Autonomia amministrativa. Idealmente, una organizzazione dovrebbe essere libera di scegliere la propria politica di gestione della rete, pur riuscendo a stabilire connessioni con il resto della rete.
Per risolvere questi problemi i router vengono organizzati in sistemi autonomi (AS). Un sistema autonomo è un insieme di router amministrati da una stessa entità (un provider o un'azienda). I router interni ad un sistema autonomo eseguono tutti lo stesso algoritmo di instradamento e si scambiano informazioni.
L'algoritmo di instradamento in esecuzione in un sistema autonomo è chiamato protocollo di routing intra-autonomous-system. Naturalmente, sarà necessario interconnettere gli autonomous system, quindi uno o più router in un sistema autonomo deve avere il compito aggiuntivo di inviare i pacchetti a destinazioni esterne all'AS. Questi router sono denominati "gateway router".
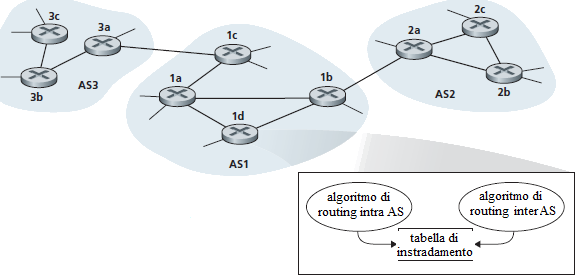
La figura mostra un esempio con tre Sistemi Autonomi: AS1, AS2, ed AS3. Le linee spesse indicano connessioni dirette tra coppie di router. Le linee sottili tra i router rappresentano sottoreti che sono collegate alle interfacce dei router. Nel sistema autonomo AS1 ci sono quattro router 1a, 1b, 1c, e 1d, i quali usano il protocollo di instradamento intra-AS preferito in AS1. Ognuno di questi quattro router conosce il percorso ottimale per instradare pacchetti verso qualsiasi destinazione contenuta in AS1. Analogamente i sistemi autonomi AS2 ed AS3 hanno i propri tre router. Gli algoritmi di instradamento adottati nei tre sistemi autonomi potrebbero essere tutti diversi. I router 1b, 1c, 2a, e 3a sono "gateway router".
I router sono in grado di determinare i percorsi tra qualsiasi coppia sorgente-destinazione interna al sistema autonomo di cui fanno parte. Come fa un router di un sistema autonomo a sapere come instradare un pacchetto destinato ad un host esterno al sistema autonomo? Se il sistema autonomo avesse un solo gateway router che lo connette solo ad un altro sistema autonomo, la risposta è ovvia perchè non ci sono alternative.
In questo caso, poichè l'algoritmo di instradamento intra-AS del sistema autonomo ha determinato il percorso di costo minimo da ciascuno dei router interni verso il gateway router, ogni router interno sa come instradare i pacchetti. Il gateway router, alla ricezione di un pacchetto, invia il pacchetto sull'unico canale che porta all'esterno del sistema autonomo. Il sistema autonomo sull'altro capo del canale, si assume la responsabilità di instradare il pacchetto verso la destinazione.
Ad esempio, si supponga che il router 2b riceva un pacchetto la cui destinazione è esterna ad AS2. Il router 2b consulta la tabella di instradamento e decide di consegnare il pacchetto al router 2a o 2c, a seconda di quale è specificato nella tabella di instradamento. Il pacchetto arriverà al gateway router 2a che lo invia al router 1b. A questo punto il compito del sistema autonomo è finito.
Tutto questo vale se il sistema autonomo ha una sola via di uscita. Ma come cambiano le cose se il sistema autonomo sorgente ha due o più canali, cioè due o più gateway router, che portano ad altri sistemi autonomi? In questa situazione bisogna decidere a quale gateway router consegnare i pacchetti uscenti.
Ad esempio, si consideri un router in AS1 e si supponga che questo riceva un pacchetto la cui destinazione si trova in un sistema autonomo esterno. Il router deve scegliere tra i router 1b e 1c. Per prendere questa decisione, AS1 ha bisogno: (1) di apprendere quali destinazioni sono raggiungibili attraverso AS2 e quali destinazioni sono raggiungbili attraverso AS3, e (2) propagare queste informazioni di raggiungibilità a tutti i router interni di AS1, per consentire a ciascun router di configurare la propria tabella di instradamento affinchè riesca a gestire le destinazioni esterne all'AS.
Questi due compiti, ottenere le informazioni di raggiungibilità dagli AS limitrofi e propagarle a tutti irouter interni all'AS, sono affidati al protocollo di routing intra-AS. Poichè il protocollo di routing inter-AS riguarda la comunicazione tra due AS, i due sistemi autonomi in comunicazione devono usare lo stesso protocollo di routing inter-AS, chiamato BGP4.
La figura mostra che ogni router riceve informazioni da un protocollo di routing intra-AS e da un protocollo di routing inter-AS, ed usa le informazioni di entrambi i protocolli per calcolare la sua tabella di instradamento.
Ad esempio, si consideri una sottorete x (identificata dal suo indirizzo IP), e si supponga che AS1 apprenda dal protocollo di routing inter-AS che la sottorete x è raggiungibile da AS3 ma non è raggiungibile da AS2. Allora AS1 propaga questa informazione a tutti i suoi router interni. Quando il router 1d apprende che la subnet x è raggiungibile da AS3, quindi dal gateway 1c, determina, dall'informazione che ha avuto dal protocollo intra-AS, l'interfaccia del router che si trova sul percorso di costo minimo dal router sorgente 1d al gateway router 1c. Si indichi con I tale interfaccia. Il router 1d inserisce la riga (x, I) nella tabella di instradamento. Questo esempio serve solo per fornire un'idea generale del meccanismo di instradamento. Una descrizione più dettagliata verrà presentata nel paragrafo dedicato al protocollo BGP.
Continuando con l'esempio, si supponga che AS2 ed AS3 siano connessi ad altri sistemi autonomi (non mostrati nella figura). Inoltre si supponga che AS1 apprenda dal protocollo di instradamento inter-AS che la subnet x è raggiungibile sia da AS2, tramite il gateway router 1b, che da AS3, tramite il gateway router 1c. AS1 dovrebbe propagare questa informazione a tutti i suoi router, compreso il router 1d. Per calcolare la sua tabella di instradamento, il router 1d, dovrebbe determinare a quale gateway, 1b o 1c, conviene inviare i pacchetti che sono destinati alla subnet x. La soluzione adottata nella pratica è quella di usare un algoritmo hot-potato. Nell'algoritmo di instradamento hot-potato, un pacchetto (la patata bollente) viene consegnato quanto più rapidamente possibile (perchè scotta - cioè al minimo costo). La scelta avviene preferendo il gateway router che ha il minimo costo, dal router sorgente al gateway, tra tutti i gateway che consentono di raggiungere la destinazione. In questo esempio, l'algoritmo hot-potato, in esecuzione su 1d, usa l'informazione ricevuta dal protocollo di routing intra-AS per determinare i costi dei cammini verso 1b e 1c, per poi scegliere il percorso di costo minimo. Dopo aver scelto il cammino, il router 1d aggiunge la riga per raggiungere la subnet x, nella sua tabella di instradamento.
La figura seguente riepiloga le azioni intraprese dal router 1d per inserire la nuova riga per la subnet x nella tabella di instradamento.
Apprende da un protocollo inter-AS che la subnet x è raggiungibile attraverso più gateway. |
→ | Usa le informazioni di routing ricevute dai protocolli intra-AS per determnare i costi dei cammini di costo minimo verso ciascuno dei gateway. |
→ | L'algoritmo di instradamento Hot Potato sceglie il gateway che ha il minimo costo. |
→ | Determina, dalla tabella di instradamento, l'interfaccia I che porta al gateway di costo minimo. Inserisce la riga (x, I) nella tabella di instradamento. |
Quando un AS apprende, da un vicino, la raggiungibilità di una nuova destinazione, l'AS può consegnare questa informazione anche ad altri AS adiacenti. Ad esempio, se AS1 viene a sapere da AS2 che la subnet x è raggiungibile tramite AS2, AS1 potrebbe comunicare ad AS3 che x è raggiungibile attraverso AS1. In questo modo, se AS3 ha bisogno di instradare un pacchetto destinato a x, AS3 dovrebbe consegnare il pacchetto ad AS1, che lo dovrebbe passare ad AS2.
Il BGP decide quali destinazioni comunicare ai suoi vicini, principalmente per motivi economici anzichè tecnici.
Internet consiste di una maglia di ISP interconnessi. Si potrebbe pensare che i router in un ISP, e i canali che li interconnettono, formano un sistema autonomo. In genere questo è vero, ma nella pratica, molti ISP partizionano le loro reti in più AS.
In conclusione, i problemi dell'estensione geografica e dell'amministrazione vengono risolti definendo i sistemi autonomi. In un sistema autonomo, tutti i router adottano lo stesso algoritmo di instradamento intra-AS. Tra gli AS, invece, si usa lo stesso algoritmo di instradamento inter-AS. In questo modo il problema dell'estensione geografica è risolto perchè un router intra-AS ha bisogno di conoscere solo i router interni all'AS. Il problema dell'autorità amministrativa è risolto perchè una organizzazione può scegliere il protocollo di routing inter-AS che preferisce, per propagare le informazioni di raggiungibilità
Il Routing in Internet
Il compito dei protocolli di routing in Internet è quello di determinare il percorso che deve scegliere un datagramma, da un certa sorgente ad una certa destinazione. Si ricordi che un sistema autonomo è formato da un insieme di router che sono controllati da una stessa autorità amministrativa e tecnica, e che tutti comunicano tra loro per mezzo dello stesso protocollo di routing. Ogni AS, a sua volta, contiene molte sottoreti.
Il protocollo di routing Intra-AS in Internet: RIP
Un protocollo di routing intra-AS è usato per determinare come eseguire l'instradamento all'interno di un sistema autonomo. I protocolli di routing Intra-AS sono anche noti come "interior gateway protocol". In Internet si sono diffusi due protocolli per instradare pacchetti all'interno di un sistema autonomo: il Routing Information Protocol (RIP) e l'Open Shortest Path First (OSPF). Un protocollo di routing di tipo OSPF è il protocollo IS-IS (Intermediate System-Intermediate System).
Il RIP fu uno dei primi protocolli di instradamento intra-AS di Internet, ed oggi è ancora ampiamente usato. Il RIP è un protocollo di tipo Distance Vector che opera in un modo molto simile alla formulazione originaria di Bellman-Ford. La metrica usata dal RIP è costituita da una sola variabile: il numero di router attraversati (hop). Cioè ogni router attraversato ha costo 1. Nell'algoritmo Distance Vector i costi sono associati ai canali che si trovano tra coppie di router. Nel RIP (ed anche in OSPF) i costi sono definiti da un router sorgente ad una subnet destinazione. Il RIP usa il termine hop con il significato di numero di sottoreti attraversate lungo il cammino ottimale dal router sorgente alla sottorete destinazione compresa.
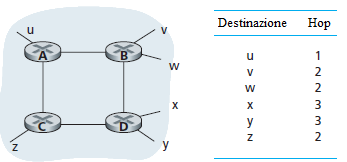
La figura mostra un AS con sei subnet. La tabella indica il numero di salti (hop) dal router sorgente A a ciascuna delle sottoreti. Il massimo costo di un cammino può essere 15, quindi l'uso del RIP in un sistema autonomo, impone che non ci siano più di 15 salti tra due host qualsiasi. Nel protocollo Distance Vector, i router adiacenti si scambiano i distance vector, i quali, per ogni router, contengono la stima corrente dei cammini di lunghezza minima, da quel router a ciascuna sottorete nell'AS. Nel RIP, gli aggiornamenti dei costi tra router adiacenti vengono scambiati ogni 30 secondi circa usando un messaggio RIP response. Il messaggio di risposta inviato da un router o da un host contiene un elenco di, al massimo, 25 sottoreti destinazione interne all'AS, e la distanza del mittente da ciascuna di quelle sottoreti. I messaggi di risposta sono anche noti come RIP advertisement.
Un semplice esempio chiarirà il ruolo dei RIP advertisement. Si Consideri la porzione di un AS come mostrata nella figura:
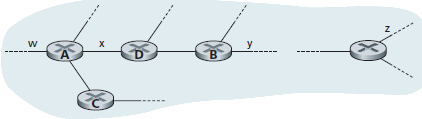
In questa figura, le linee che connettono i router denotano sottoreti. Solo i router selezionati (A, B, C e D) e le sottoreti (w, x, y e z) sono state etichettate. Le linee punteggiate indicano che l'AS si estende ancora; quindi in questo AS ci sono ancora molti router e canali non mostrati.
Ogni router mantiene una tabella di instradamento RIP. Eliminando la colonna Next-Hop dalla tabella di instradamento, si ottiene il Distance Vector. La Figura seguente mostra la tabella di routing per il router D.
| Destinazione | Next Router | Numero di salti verso la Destinazione |
| w | A | 2 |
| y | B | 2 |
| z | B | 7 |
| x | - | 1 |
| … | … | … |
Si noti che la tabella di routing ha tre colonne. La prima colonna indica la sottorete di destinazione, la seconda colonna indica l'identità del router successivo lungo il percorso più breve verso la sottorete di destinazione, e la terza colonna indica il numero di salti (cioè, il numero di sottoreti che devono essere attraversate (compresa la sottorete destinazione) per raggiungere la sottorete destinazione lungo il percorso più breve.
Per questo esempio, la tabella indica che per inviare un datagramma dal router D alla sottorete destinazione w, il datagramma deve prima essere inoltrato al router adiacente A; la tabella indica anche che la sottorete destinazione w è raggiungibile con due hop di distanza lungo il percorso più breve. Allo stesso modo, la tabella indica che la sottorete z è raggiungibile con sette hop attraverso il router B. Una tabella di routing possiede una riga per ogni sottorete in AS, ma il RIP versione 2 consente di specificare una sola riga utilizzando tecniche di aggregazione dei percorsi. La tabella nella figura seguente, e le tabelle successive, sono solo parzialmente complete.
Si supponga ora che dopo 30 secondi, il router D riceva dal router A il messaggio di aggiornamento mostrato nella tabella.
| Destinazione | Next Router | Numero di salti verso la Destinazione |
| z | C | 4 |
| w | - | 1 |
| x | - | 1 |
| … | … | … |
Si noti che questo messaggio è la tabella di routing del router A. Queste informazioni indicano, in particolare, che la sottorete z si trova solo quattro salti distante dal router A. Il Router D, dopo aver ricevuto questa informazione, opera una fusione tra il Distance Vector e la vecchia tabella di routing. In particolare, il router D apprende che vi è un percorso attraverso il router A verso la sottorete z che è più breve del percorso attraverso il router B. Così, il router D aggiorna la sua tabella di routing per utilizzare il percorso più breve, come mostrato nella Figura.
| Destinazione | Next Router | Numero di salti verso la Destinazione |
| w | A | 2 |
| y | B | 2 |
| z | A | 5 |
| … | … | … |
Ci si potrebbe chiedere, come mai il percorso più breve per la sottorete z è diventato ancora più breve. La ragione potrebbe essere che l'algoritmo distribuito Distance Vector è ancora in fase di convergenza, o forse sono stati aggiunti nuovi collegamenti e/o router all'AS, che creano percorsi più brevi nell'AS.
Si prendano in considerazione alcuni degli aspetti relativi al funzionamento effettivo del RIP. Si ricordi che lo scambio di messaggi RIP tra i router avviene ogni 30 secondi. Se un router non riceve dal suo vicino almeno un messaggio ogni 180 secondi, il router assume che quel vicino non è più raggiungibile; ciò potrebbe essere dovuto al router che si è disconnesso, oppure al canale che ha subito un'interruzione. Quando questo accade, il RIP modifica la tabella di routing locale e quindi propaga queste informazioni inviando i messaggi di notifica ai suoi router vicini (quelli che sono ancora raggiungibili). Un router può anche richiedere informazioni sul costo che il suo vicino ha calcolato per una determinata destinazione, utilizzando un messaggio di richiesta RIP. I router si scambiano messaggi di richieste RIP e di risposta RIP appoggiandosi sul protocollo UDP, utilizzando il numero di porta 520. Il segmento UDP si propaga tra i router in un datagramma IP standard. Il fatto che il RIP utilizzi un protocollo del livello di trasporto (UDP) che si appoggia su un protocollo del livello rete (IP) per implementare la funzionalità a livello di rete (un algoritmo di instradamento) può apparire (è!) una violazione del modello di riferimento. Questo fatto si comprende guardando un po' più a fondo il modo in cui il RIP è implementato.
La figura mostra uno schema di come il RIP è implementato in un sistema UNIX, per esempio, una stazione di lavoro UNIX che funge da router. Un processo chiamato routed (pronunciato "route-dee") esegue il RIP, cioè, gestisce le informazioni di routing e scambia messaggi con i processi di routing in esecuzione nei router adiacenti. Poichè il RIP è implementato come un processo del livello applicazione (anche se molto speciale perchè è in grado di manipolare le tabelle di routing all'interno del kernel UNIX), può inviare e ricevere messaggi attraverso un socket standard e utilizzare un protocollo di trasporto standard. Come si vede, il RIP è implementato come un protocollo di livello di applicazione che si appoggia su UDP.
Il protocollo di routing Intra-AS in Internet: OSPF
Anche l'algoritmo di instradamento OSPF, come il RIP, è ampiamente usato in Internet. L'algoritmo OSPF, ed il suo simile IS-IS, sono impiegati nei livelli superiori della gerarchia degli ISP, mentre il RIP è impiegato nei livelli inferiori della rete gerarchica di un ISP e nelle reti aziendali. In OSPF, Open indica che le specifiche del protocollo sono disponibili per chiunque voglia usarle (a differenza del protocollo EIGRP della cisco). OSPF fu concepito come il successore del RIP e, come tale, presenta un certo numero di caratteristiche avanzate. OSPF é un protocollo di tipo Link State che usa la trasmissione a diffusione in broadcast per propagare le informazioni di routing e usa l'algoritmo di Dijkstra per calcolare i cammini di costo minimo.
Con OSPF, un router raccoglie le informazioni da tutti i router della rete e dispone, quindi, della mappa (cioè un grafo) completa dell'intero sistema autonomo. Il router applica l'algoritmo di Dijkstra per determinare una topologia ad albero, in cui la radice è il router stesso, e i rami sono i cammini di costo minimo tra le sottoreti, L'amministratore della rete assegna i costi ai canali. L'amministratore potrebbe decidere di assegnare costo 1 a tutti i canali, ottenendo così il criterio che il cammino di costo minimo è quello con il minimo numero di hop, oppure, potrebbe decidere di assegnare a ciascun canale un costo che sia inversamente proporzionale alla velocità della linea, in modo da ridurre il traffico sui canali che hanno una banda stretta.
OSPF non obbliga ad usare una particolare metrica, ma fornisce un meccanismo (il protocollo) per determinare i cammini di costo minimo in base alla metrica adottata.
In OSPF un router invia le informazioni di routing, in broadcast, a tutti gli altri router contenuti nel sistema autonomo. Con OSPF, un router genera le informazioni di routing verso tutti gli altri router del sistema autonomo, non solo ai router adiacenti, ogni volta che si verifica un evento legato ad una variazione di stato del canale (ad esempio una variazione del costo o l'indisponibilità del canale). La trasmissione delle informazioni di routing, comunque, avviene anche ogni 30 minuti.
L'aggiornamento periodico serve per dare robustezza all'algoritmo di tipo Link State.
Gli OSPF advertisement sono contenuti in messaggi OSPF che sono trasportati direttamente in pacchetti IP, con il campo "protocollo di livello superiore" codificato con 89, per indicare OSPF. Di conseguenza, lo stesso protocollo OSPF deve implementare le funzionalità quali l'affidabilità del trasferimento e il broadcast. Il protocollo OSPF controlla anche che i canali siano operativi (tramite un pacchetto "HELLO" che viene inviato ai vicini) e consente ad un router OSPF di ottenere il Link-State packet data base da un vicino.
Alcune delle caratteristiche di OSPF sono:
Sicurezza. Gli scambi tra i router OSPF (ad esempio i messaggi di aggiornamento) possono essere autenticati. Con l'autenticazione solo i router riconosciuti possono partecipare al protocollo OSPF in un sistema autonomo. Un attaccante, quindi, non ha la possibilità di generare informazioni di routing false per danneggiare le tabelle di instradamento. Per default, i pacchetti OSPF tra i router non sono autenticati e potrebbero essere falsificati. Si possono configurare due tipi di autenticazioni: semplice ed MD5. Con l'autenticazione semplice, i router condividono una stessa password. Quando un router invia una informazione di aggiornamento OSPF, inserisce nel pacchetto anche la password in chiaro. Quindi questa modalità non è sicura. L'autenticazione MD5 si basa sull'uso di chiavi segrete condivise conosciute da tutti i router. Per ogni pacchetto OSPF inviato, il router calcola l'hash MD5 del contenuto del pacchetto concatenato con la chiave segreta, il risultato viene accodato al pacchetto OSPF. Il router ricevitore calcola l'hash MD5 del contenuto del pacchetto concatenato con la chiave segreta che condivide e confronta questo risultato con il valore accodato al pacchetto. Se i due valori coincidono il pacchetto è autenticato. Esiste anche la possibilità che un attaccante, registri una serie di pacchetti OSPF e li ripeta a distanza di tempo (attacco di ripetizione). Per impedire questo attacco, i pacchetti contengono un numero di sequenza.
Percorsi multipli con costo uguale. Quando ci sono molti cammini di costo minimo uguale verso la stessa destinazione, OSPF consente di usarli tutti (cioè non è necessario usare solo un percorso per trasmettere tutto il traffico).
Supporto integrato per il routing unicast e multicast. Il multicast OSPF è un'estensione di OSPF. Questo usa il database esistente e aggiunge un nuovo tipo di messaggio link-state al meccanismo di broadcast.
Supporto per la gerarchia in un singolo dominio di routing. La caratteristica più avanzata di OSPF è l'abilità di strutturare gerarchicamente un sistema autonomo.
In un sistema autonomo, OSPF può essere configurato gerarchicamente in aree. In ogni area viene applicato un algoritmo OSPF, in cui ciascun router invia i suoi pacchetti link state in broadcast solo ai router contenuti nell'area. In ciascuna area, uno o più router di frontiera (border router) sono responsabili dell'instradamento dei pacchetti all'esterno dell'area. Infine, una solo area nel sistema autonomo è configurata come area di backbone (dorsale). Il compito principale della backbone area è di instradare il traffico tra le altre aree nel sistema autonomo. L'area di backbone contiene tutti i router di frontiera presenti nel sistema autonomo, ma può contenere anche router che non sono di frontiera per nessuna area. Il routing inter-area in un sistema autonomo richiede che i pacchetti siano prima consegnati ad un router di frontiera dell'area (intra-area routing), e poi, attraverso la backbone area, al router di frontiera dell'area di destinazione, e quindi instradato alla destinazione finale.
Scelta dei costi dei canali
Si è ipotizzato che i costi dei canali siano noti, che sia in escuzione l'algoritmo OSPF e che il flusso del traffico è determinato dalla tabella di instradamento, calcolata dall'algoritmo Link-State. Espresso in termini di causa ed effetto, dopo aver assegnato i costi dei canali si ottengono di conseguenza i cammini di costo minimo. Da questo punto di vista, i costi dei canali riflettono il costo dell'utilizzazione di un canale (ad esempio, se si sceglie di assegnare il costo del canale come un valore inversamente proporzionale alla capacità del canale, allora, per forzare l'utilizzo dei canali ad alta capacità, a questi si devono assegnare valori bassi) L'algoritmo di Dijkstra minimizza il costo globale.
In pratica, la relazione causa ed effetto tra i costi dei canali e i cammini di costo minimo può essere invertita, per permettere ad un amministratore del sistema autonomo di decidere come preferisce bilanciare il traffico. Ad esempio, se un operatore della rete ha ottenuto una stima del flusso del traffico entrante in ogni punto di accesso e destinato ad ogni punto di uscita, l'operatore può determinare un preciso piano di instradamento del flusso del traffico in transito dai punti di accesso ai punti di uscita, che minimizzi la massima utilizzazione globale dei canali della rete.
Ma con un algoritmo di routing come OSPF, le principali manovre che l'operatore può applicare per l'ottimizzazione dell'instradamento dei flussi attraverso la rete sono i pesi da assegnare ai canali. Così, al fine di raggiungere l'obiettivo di minimizzare il massimo utilizzo del canale, l'operatore deve trovare un insieme di pesi da dare ai canali che raggiunga questo obiettivo. Si tratta di un'inversione della relazione di causa ed effetto: si conosce l'instradamento desiderato dei flussi, e si deve determinare il peso dei canali OSPF, in modo che i risultati dell'algoritmo di routing OSPF in questo calcolo dell'itinerario forniscano esattamente i flussi desiderati.
Routing Inter-AS: BGP
Si è visto come gli ISP usino RIP e OSPF per determinare i percorsi ottimali tra coppie sorgente-destinazione interne allo stesso AS. Adesso si esamina come vengono determinati i cammini tra coppie sorgente-destinazione che attraversano più sistemi autonomi. Il Border Gateway Protocol versione 4 (BGP4) è lo standard de facto dei protocolli di routing inter-AS in Internet. Come protocollo di routing inter-AS, BGP fornisce ad ogni AS gli strumenti per:
Ottenere l'informazione di raggiungibilità delle sottoreti dagli AS adiacenti.
Propagare l'informazione di raggiungibilità a tutti i router interni all'AS.
Determinare i cammini migliori verso le subnet, sulla base delle informazioni di raggiungibilità e la politica dell'AS.
La caratteristica più importante di BGP è che permette ad ogni sottorete di farsi conoscere dal resto di Internet. Una sottorete invia un pacchetto di "saluti" e il BGP assicura che tutti i sistemi autonomi di Internet apprendano l'esistenza della sottorete e del modo in cui possono raggiungerla. In assenza del BGP ogni sottorete resterebbe isolata e sconosciuta
Generalità del BGP
BGP è estremamente complesso; Sono stati scritti numerosi libri sul BGP, e restano ancora molti problemi irrisolti. Addirittura, dopo aver letto i libri e le RFC, il BGP resta ancora molto difficile da comprendere; sarebbero necessari mesi di esperienza pratica, come progettista o amministratore di un ISP, per impadronirsi pienamente delle sue funzionalità. Siccome BGP è il protocollo che fa funzionare Internet, una conoscenza, almeno rudimentale, è ncessaria. Si inizia,quindi, a descrivere come funziona il BGP nel contesto di una semplice rete:
In questa descrizione si sfrutta l'idea del routing gerarchico.
In BGP, coppie di router si scambiano informazioni di routing appoggiandosi su connessioni TCP usando la porta 179.
Le connessioni semi-permanenti TCP, per la rete in esame, sono mostrate nella figura seguente:
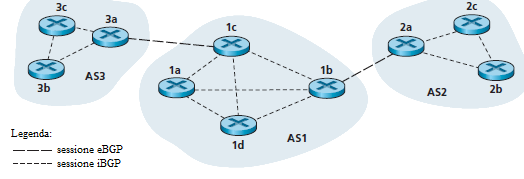
Esiste una connessione TCP del BGP per ogni canale che connette direttamente due router che si trovano in due diversi AS; Nella figura c'è una connessione TCP tra i gateway router 3a e 1c, ed un'altra connessione TCP tra i gateway router 1b e 2a. Ci sono anche connessioni TCP semipermanenti tra i router interni ad un sistema autonomo. In particolare, la figura mostra una configurazione comune di una connessione TCP per ogni coppia di router interni ad un AS, creando una topologia a maglia di connessioni in un AS. Per ogni connessione TCP, i due router agli estremi di una connessione sono chiamati BGP_peers, e la connessione TCP insieme ai messaggi BGP inviati su di essa è detta sessione BGP. Una sessione BGP che coinvolge due AS è detta una sessione BGP esterna (eBGP), mentre una sessione tra router dello stesso sistema autonomo è chiamata sessione BGP interna (iBGP). Nella figura, le sessioni eBGP sono mostrate con linee a tratteggio lungo, le sessioni iBGP sono indicate con linee a tratteggio breve. Notare che in questa figura le linee di sessione non sempre corrispondono a canali fisici.
Il BGP consente ad ogni AS di apprendere quali destinazioni sono raggiungibili attraverso i suoi AS vicini. In BGP, le destinazioni non sono host ma sono prefissi in notazione CIDR, dove ogni prefisso rappresenta una sottorete o un insieme di sottoreti.
Ad esempio, si supponga che ci siano quattro sottoreti in AS2: 138.16.64/24, 138.16.65/24, 138.16.66/24, e 138.16.67/24, allora AS2 potrebbe aggregare i prefissi per queste quattro sottoreti ed usare BGP per informare AS1 che in AS2 ci sono tutte le destinazioni aventi il prefisso 138.16.64/22. Come altro esempio, si supponga che solo le prime tre sottoreti si trovano in AS2, mentre la quarta sottorete, 138.16.67/24, si trova in AS3. Allora poichè i router instradano i datagrammi usando il prefisso più lungo con cui trovano una corrispondenza, AS3 comunica ad AS1 che contiene la rete con il prefisso più specifico 138.16.67/24, ed AS2 dovrebbe comunicare ad AS1 il prefisso aggregato 138.16.64/22.
Adesso si esamini come il BGP dovrebbe distribuire le informazioni dei prefissi di rete, relativi alla raggiungibilità, sulle sessioni BGP. Usando la sessione eBGP tra i gateway router 3a e 1c, AS3 invia ad AS1 la lista dei prefissi che sono raggiungibili da AS3, ed AS1 invia ad AS3 la lista dei prefissi che sono raggiungibili da AS1. Analogamente, AS1 ed AS3 scambiano le informazioni dei prefissi, relativi alla raggiungibilità delle loro sottoreti, tramite i gateway router 1b e 2a. Inoltre, quando un gateway router, di un AS, riceve i prefissi appresi eBGP, il gateway router usa le sue sessioni iBGP per distribuire i prefissi agli altri router nell'AS. Così tutti i router in AS1 apprendono i prefissi di AS3, compreso il gateway router 1b. Il gateway router 1b in AS1 può perciò ripetere le informazioni dei prefissi di AS3 ad AS2. Quando un qualsiasi router apprende un nuovo prefisso, inserisce una nuova riga nella sua tabella di instradamento.
Ottenere una presenza in Internet
Si supponga di aver creato una piccola rete, in cui ci sono un certo numero di server, tra cui un server web, un server di posta elettronica ed un server DNS. A questo punto si desidera conquistare la visibilità sul web, ed offrire al pubblico la possibilità di comunicare via mail con il personale dell'azienda. Come prima operazione è necessario ottenere la connettività a Internet. Ciò viene ottenuto stipulando un contratto con un ISP locale. L'azienda deve avere un router che si connette, tramite il canale concesso dall'ISP, al router dell'ISP. Il canale potrebbe essere una linea ADSL, un canale dedicato o altro. L'ISP fornirà anche un intervallo di indirizzi IP, del tipo a.b.c.d/24. Ottenuta la connettività: fisica e l'intervallo di indirizzi IP, si procederà assegnando un indirizzo IP al server web, un indirizzo IP al server di posta, un indirizzo IP al server DNS, un indirizzo IP al router e un indirizzo IP ad ognuno dei rimanenti dispositivi della rete.
Dopo aver stipulato il contratto con l'ISP, bisogna anche registrare un nome di dominio. Ad esempio, se il nome dell'azienda è xyz, si vorrebbe ottenere il nome di dominio xyz.it. Questo nome di dominio deve essere anche presente nel DNS. Cioè i visitatori esterni che desiderano contattare uno dei server aziendali, deve interrogare il DNS con il nome di dominio, per ottenere l'indirizzo IP. Sarà necessario registrare il nome del dominio con associato il server DNS aziendale. L'ente autorizzato alla registrazione inserisce una riga nel DNS per associare il nome del dominio all'indirizzo IP del server DNS aziendale. Terminata questa operazione, ogni utente che conosce il nome del dominio (es. xyz.it) potrà ottenere l'indirizzo IP del server DNS aziendale dal server DNS di sistema.
Ma affinchè le persone possano poi conoscere l'indirizzo IP del server web, sarà necessario inserire, nel DNS aziendale, una riga che metta in corrispondenza il server web con il suo indirizzo IP. Ogni altro server, ad esempio il mail server, che deve essere raggiungibile dall'esterno deve avere una riga di corrispondenza (nome server - Indirizzo IP) nel DNS aziendale.
In questo modo, se Alice desidera navigare nel server web aziendale, il DNS di sistema contatta il server DNS aziendale, trova l'indirizzo IP del server web aziendale e lo fornisce ad Alice. Alice stabilisce una connessione TCP con il server web.
Per consentire agli utenti esterni l'accesso al server web, resta ancora un'altra operazione necessaria e cruciale. Si pensi cosa succede quando Alice, che conosce l'indirizzo IP del server web aziendale, invia un datagramma (ad esempio la richiesta di apertura connessione) a quell'indirizzo IP. Questo datagramma viaggerà attraverso vari AS della rete e raggiungerà il server web. Quando uno dei router riceve il datagramma, cerca una riga nella tabella di instradamento per determinare su quale canale deve trasmettere il pacchetto per farlo giungere a destinazione. Quindi i router hanno bisogno di conoscere l'esistenza del prefisso della rete (o un prefisso aggregato). A questa notifica ha provveduto il BGP. Più precisamente, quando è stato stipulato il contratto con l'ISP locale e si è ottenuto il prefisso di rete (cioè un intervallo di indirizzi), l'ISP locale, tramite il BGP, ha trasmesso questo prefisso agli altri ISP a cui è connesso. Quegli ISP, a loro volta, useranno il BGP per propagare la notifica. Ad un certo punto tutti i router in Internet conosceranno il prefisso della rete e saranno in grado di instradare i pacchetti destinati al server web e al server mail aziendale.
Attributi del percorso e cammini BGP
In BGP un sistema autonomo è identificato da un numero univoco assegnato da un organismo internazionale. Quando un router notifica un prefisso di rete durante una sessione BGP include anche un certo numero di attributi. In BGP, un prefisso con i suoi attributi è detto rotta. I peer BGP si scambiano le notifiche delle rotte. Due dei più importanti attributi sono AS-PATH e NEXT-HOP:
AS-PATH. Questo attributo contiene gli AS attraverso cui il messaggio di notifica del prefisso è passato. Quando un prefisso passa in un AS, l'AS aggiunge il suo AS-number all'attributo AS-PATH. Ad, esempio, con riferimento alla figura precedente, si supponga che il prefisso 138.16.64/24 venga comunicato da AS2 ad AS1; Se AS1 trasmette il prefisso as AS3, l'attributo AS-PATH adesso dovrebbe essere "AS2 AS1". I router usano l'attributo AS-PATH per prevenire il verificarsi di una trasmissione ciclica dei messaggi di notifica. Infatti, se un router vede che il suo AS è contenuto nella lista dell'attributo AS-PATH, scarta il messaggio. I router usano l'AS-PATH per scegliere tra percorsi multipli verso lo stesso prefisso.
L'attributo NEXT-HOP ha un ruolo importante nel fornire il canale ai protocolli inter-AS e intra-AS. Il NEXT.HOP è l'indirizzo dell'interfaccia del router da cui inzia l'AS-PATH. Ancora con riferimento alla figura precedente, si consideri cosa succede quando il gateway router 3a nell'AS3 notifica una rotta al gateway router 1c nell'AS1 usando una sessione eBGP. La rotta include il prefisso da notificare, che verrà indicato con x ed un AS-PATH al prefisso. Questo messaggio di notifica contiene anche il NEXT-HOP, che è l'indirizzo IP dell'interfaccia del router 3a che conduce a 1c. (si ricordi che ogni interfaccia del router ha un proprio indirizzo IP). Dopo che il router ha appreso, da iBGP, questo nuovo instradamento verso x, il router 1d dovrebbe instradare i pacchetti verso x lungo la rotta, cioè il router 1d deve inserire la riga (x, l) nella sua tabella di instradamento, dove l è la sua interfaccia da cui inizia il percorso di costo minimo da 1s verso il gateway router 1c. Per determinare l, 1d fornisce l'indirizzo IP nell'attributo NEXT-HOP al suo modulo di instradamento intra-AS. Notare che l'algoritmo di instadamento intra-AS ha determinato il percorso di costo minimo verso tutte le sottoreti collegate ai router in AS1, compreso verso la sottorete sul canale tra 1c e 3a. Da questo percorso di costo minimo da 1d alla sottorete tra 1c e 3a, 1d determina la sua interfaccia l del router da cui comincia questo cammino e poi aggiunge la riga (x, l) alla tabella di instradamento. In definitiva, si può concludere che l'attributo NEXT-HOP serve per consentire ai router di configurare correttamente la tabella di instradamento.
La figura mostra un'altro caso in cui l'attributo NEXT-HOP è necessario.
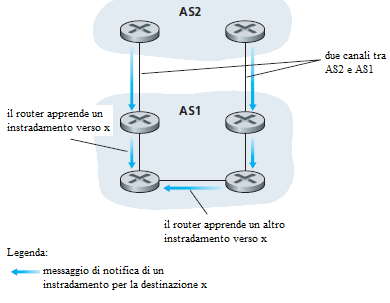
In questa figura, AS1 ed AS2 sono connessi da due canali equivalenti. Un router in AS1 potrebbe apprendere due diversi instradamenti verso lo stesso prefisso x. Queste due rotte potrebbero avere lo stesso attributo AS-PATH verso x, ma potrebbero avere valori differenti dell'attributo NEXT-HOP corrispondenti ai differenti canali equivalenti. Usando i valori NEXT-HOP e l'algoritmo di routing intra-AS, il router può determinare il costo del cammino attraverso ciascuno dei canali equivalenti, e poi applicare l'algoritmo di routing hot-potato per determinare l'interfaccia appropriata.
Il BGP include attributi che permettono ai router di assegnare metriche preferenziali agli instradamenti, ed un attributo che indica come il prefisso era stato inserito in BGP all'AS di origine.
Quando un gateway router riceve un messaggio di notifica di un instradamento, usa la sua politica di importazione per decidere se accettare o filtrare l'instradamento e se impostare qualche attributo, quali le metriche preferenziali del router. La politica di importazione può filtrare un instradamento perchè l'AS potrebbe non volere inviare traffico su uno degli AS elencati nell'attributo AS-PATH dell'instradamento. Il gateway router può anche filtrare un instradamento perchè è già noto come un instradamento preferenziale verso lo stesso prefisso.
Selezione dell'instradamento nel BGP
Come detto, il BGP usa le sessioni eBGP e iBGP per distribuire gli instradamenti a tutti i router contenuti in un AS. Da questa distribuzione, un router può apprendere altri instradamenti verso un prefisso, nel qual caso il router deve selezionare uno tra gli instradamenti possibili. L'input per questo processo di selezione dell'instradamento è l'insieme degli instradamenti che sono stati appresi ed accettati dal router. Se ci sono due o più instradamenti verso lo stesso prefisso, il BGP applica in sequenza le seguenti regole di eliminazione, fino a quando resta un solo instradamento:
Ai router viene assegnato un valore di preferenza locale, come uno dei suoi attributi. La preferenza locale di un instradamento potrebbe essere stata impostata dal router, oppure potrebbe essere stata appresa da un altro router nello stesso AS. Questa è una scelta che viene lasciata all'amministratore della rete. Gli instradamenti con i valori di preferenza più alti, vengono selezionati.
Dagli instradamenti rimanenti, tutti con lo stesso valore di preferenza, viene selezionato quello con l'AS-PATH più corto. Se questa fosse la sola regola per selezionare l'instradamento, allora BGP userebbe l'algoritmo Distance Vector per determinare il cammino, nel quale, però la metrica usata è il numero di AS attraversati, piuttosto che il numero di router attraversati.
Dagli instradamenti rimanenti, tutti con lo stesso valore di preferenza e con la stessa lunghezza di AS-PATH, viene selezionato l'instradamento con il NEXT-HOP più vicino. Il Router più vicino è inteso nel senso di router per il quale il costo del cammino ottimale, determinato dall'algoritmo intra-AS, è il più piccolo. Questo processo è denominato hot-potato routing.
Se restano altri instradamenti, il router usa gli identificatori BGP per scegliere l'instradamento.
Le regole di eliminazione sono anche più complicate di quelle descritte.
Politica di routing
Un semplice esempio è utile per comprendere i concetti della politica di routing del BGP.
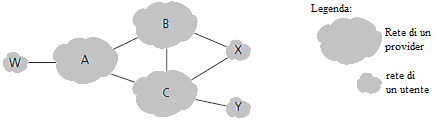
Nella figura ci sono sei sistemi autonomi interconnessi: A, B, C, W, X, ed Y. È importante notare che A, B, C, W, X, ed Y sono AS, non router. Si assume che i sistemi autonomi W, X, ed Y sono reti e che A, B, e C sono dorsali appartenenti a reti di un provider. Inoltre, A, B, e C sono reti paritetiche (nessuna svolge il ruolo di client e nessuna quello di server), e forniscono informazioni BGP complete alle loro reti di utente. Tutto il traffico che entra in una rete terminale è sicuramente destinato ad una sottorete di quella rete, e tutto il traffico che lascia una rete terminale è stato sicuramente originato da una sottorete di quella rete. Ovviamente W ed Y sono reti terminali. X è una rete che è connessa al resto della rete attraverso due differenti provider (un caso che sta diventando sempre più frequente). Ma, come W ed Y, anche X deve essere sorgente e destinazione di tutto il traffico uscente ed entrante di X. Come si dovrà implementare questo comportamento? Come si impedirà ad X di instradare il traffico tra B e C? Si può conseguire facilmente questo scopo controllando la maniera in cui gli instradamenti BGP vengono notificati. In particolare, X funzionerà come rete terminale se invia notifiche (ai suoi vicini B e C) in cui non ci sono altri percorsi destinazioni, che verso se stessa. Cioè, persino se X conoscesse un percorso, ad esempio XCY, che raggiunge la rete Y, non comunicherà quel cammino a B. Poichè B ignora che X conosce un cammino verso Y, B non dovrebbe mai instradare il traffico destinato a Y (o a C) attraverso X.
Questo semplice esempio mostra come viene usata un politica selettiva delle notifiche degli instradamenti per implementare relazioni di instradamento utenti-provider.
Si prenda la rete di un provider come riferimento, ad esempio il sistema autonomo B. Si supponga che B abbia appreso (da A) che A ha un percorso AW verso W. B può inserire l'instradamento BAW tra le sue informazioni di instradamento. Chiaramente, B vuole anche notificare il percorso BAW ai suoi utenti, X, in modo che X sappia che può instradare pacchetti destinati a W attraverso B. B dovrebbe notificare l'instradamento BAW a C? Se lo facesse, C potrebbe instradare il traffico a W attraverso CBAW. Se A, B e C sono dorsali di provider, allora B dovrebbe evitare di inviare traffico di passaggio tra A e C. B dovrebbe sapere che è compito di A e di C assicurare che C possa instradare a/da A attraverso una connessione tra A e C.
Non ci sono (al momento) regole che disciplinino il traffico attraverso le dorsali degli ISP. Il traffico che passa nella dorsale di un ISP deve avere la sorgente o la destinazione in una rete che sia cliente dell'ISP, altrimenti quel traffico passerebbe gratuitamente sui canali del provider.
BGP è lo standard de facto per il routing inter-AS di Internet. Per vedere il contenuto di alcune tabelle di instradamento estratto dai router di primo livello di un ISP, vedere http://www.routeviews.org. Le tabelle di routing BGP spesso contengono decine di migliaia di prefissi e dei corrispondenti attributi.
Come leggere una riga della tabella di instradamento di un router
Una riga della tabella di instradamento di un router, contiene almeno due colonne: il prefisso (ad esempio 138.16.64/22) e la corrispondente interfaccia di uscita. Quando arriva un pacchetto al router, l'indirizzo IP di destinazione del pacchetto viene confrontato con i prefissi contenuti nella tabella di instradamento, alla ricerca di quello che ha il maggior numero di bit nel prefisso uguali. Il pacchetto viene quindi inviato al prossimo router specificato nella colonna associata a quel prefisso. Per vedere come viene inserita una nuova riga (prefisso e linea di uscita) nella tabella di instradamento, si segua questo semplice esempio. Si assuma che il prefisso non appartiene ad un router del sistema autonomo, ma ad un altro AS.
Affinchè un prefisso venga inserito nella tabella di instradamento di un router, il router deve essere informato dell'esistenza della sottorete o di sottoreti aggregate. Questa conoscenza viene data al router da un messaggio BGP di notifica di un instradamento. Un tale messaggio di notifica può essere inviato durante una sessione eBGP (da un router in un altro AS) o durante una sessione iBGP (da un router nello stesso AS)
Dopo aver ricevuto la notifica del prefisso, il router, prima di inserire la riga nella tabella di instradamento, deve determinare la corretta porta di uscita a cui inviare i datagrammi destinati a quel prefisso. Se il router riceve più di un messaggio di notifica di uno stesso instradamento, il BGP usa il processo BGP di selezione di un instradamento, per trovare il miglior cammino per quel prefisso. Si supponga di aver trovato il miglior cammino, l'instradamento selezionato include l'attributo NEXT-HOP, che è l'indirizzo IP del primo router, esterno all'AS, che si incontra sul cammino ottimale. Il router, allora, usa il protocollo di routing intra-AS (in genere OSPF) per determinare il cammino più breve al router NEXT-HOP. A questo punto il router determina la porta di uscita da associare al prefisso, identificando il primo canale lungo il cammino di costo minimo. Il router, quindi, inserisce il prefisso e la porta di uscita nella tabella di instradamento. La tabella di instradamento, calcolata dal processore di routing, viene trascritta nella memoria associta alla linea di input del router.
Protocolli di routing INTER-AS ed INTRA-AS
Perchè esistono i due diversi protocolli di routing inter-AS e intra-AS?
Policy. Tra gli ASs, prevalgono le problematiche di policy. Potrebbe essere importante che il traffico generato in un dato AS non sia in grado di attraversare un altro specifico AS. Analogamente, un dato AS potrebbe dover controllare cosa viene trasportato dal traffico in transito tra altri AS. Ad esempio, il traffico BGP trasporta gli attributi del cammino e fornisce una distribuzione delle informazioni di routing. in modo da prendere opportune decisioni basate sulla politica di routing. Tutto il traffico in un AS Si trova sotto lo stesso controllo amministrativo, quindi i problemi della politica di instradamento all'interno di un AS, relativi alla scelta dei cammini, sono poco rilevanti.
Estensione geografica. L'abilità di un algoritmo di instradamento e le sue strutture dati di adattarsi alle dimensioni della rete, per gestire l'instradamento tra un gran numero di reti, invece, è un problema molto importante nell'instradamento inter-AS. All'interno di un AS, le variazioni delle dimensioni della rete non sono un grave problema. Se un dominio amministrativo diventa troppo grande, è sempre possibile dividerlo in due AS ed applicare il routing inter-AS tra i due nuovi AS. (Si ricordi che OSPF consente la realizzazione di un struttura gerarchica scomponendo un AS in aree.)
Prestazioni. Poichè il routing inter-AS è orientato al rispetto di una politica, la qualità (ad esempio, le prestazioni) degli instradamenti usati è un problema secondario, cioè un cammino più lungo o più costoso che soddisfa certi criteri potrebbe essere preferito rispetto ad un cammino ottimale che non soddisfa quei criteri. Tra gli AS non si usa la nozione di costo (oltre agli hop-count) dei cammini. All'interno di un AS, la politica di instradamento non impone limitazioni, si preferisce caratterizzare i cammini allo scopo di migliorare le prestazioni realizzate su un instradamento.
Instradamento Broadcast e Multicast
Finora sono stati esaminati i protocolli di routing relativi alla comunicazione unicast, cioè punto-punto, in cui un nodo sorgente invia un pacchetto ad un solo nodo destinazione. L'instradamento broadcast è un servizio del livello rete, che provvede alla consegna di un pacchetto generato da un nodo sorgente a tutti i nodi della rete; L'instradamento multicast consente ad un nodo sorgente di inviare la copia di un pacchetto a un gruppo degli altri nodi della rete.
Algoritmi di instradamento Broadcast
Il miglior modo per realizzare la comunicazione broadcast potrebbe essere quello in cui il nodo mittente invia una copia del pacchetto a ciascuna destinazione, come mostra la figura.

Dati N nodi destinazione, il nodo sorgente crea N copie del pacchetto, inserisce l'indirizzo di destinazione in ogni copia del pacchetto e trasmette i pacchetti usando il routing unicast. Questo approccio al broadcasting è semplice, non si affida ad un nuovo protocollo di rete e non richiede nuove funzionalità di instradamento. Ci sono, però, alcuni aspetti negativi in questo approccio. La prima osservazione che si può muovere verso questa soluzione è la sua inefficienza: Se il nodo sorgente è connesso al resto della rete tramite un solo canale, allora le N copie dello stesso pacchetto devono occupare il canale. Sarebbe più efficiente inviare una copia del pacchetto al nodo connesso all'altro estremo del canale e delegare a quel nodo il compito di produrre le copie necessarie da inviare agli altri nodi a cui è connesso. Cioè dovrebbe essere preferibile che i nodi stessi della rete (anzichè il nodo sorgente) creino le copie del pacchetto. Ad esempio, nella figura b, una sola copia del pacchetto attraversa il canale tra R1 e R2. Il pacchetto viene duplicato da R2, e una sola copia attraversa i canali tra R2 e R3 e tra R2 e R4. L'altra critica che si può muovere a questa soluzione di comunicazione in broadcast, è che si assume che il mittente conosca gli indirizzi dei destinatari. Per ottenere queste informazioni, il mittente dovrebbe usare un apposito protocollo di interrogazione dei nodi della rete. Ma questo introdurrebbe un sovraccarico di lavoro ed una complessità ad un protocollo apparentemente semplice. Un'ultima critica è relativa agli scopi del broadcasting. Si ricordi, infatti, che nel protocollo di routing di tipo Link State il broadcasting diffonde le informazioni che devono essere usate per il routing unicast. In tale situazione, in cui il broadcast è usato per creare ed aggiornare gli instradamenti unicast, dovrebbe essere indesiderabile basarsi sull'infrastruttura di instradamento unicast per realizzare il broadcast.
Tenendo presente le osservazioni sul broadcast ottenuto creando N comunicazioni unicast, sembra chiaro che bisogna consentire ai nodi della rete di duplicare il pacchetto, instradarlo e calcolare i cammini di broadcast.
Diffusione incontrollata
Con l'instradamento a diffusione, un nodo sorgente invia una copia del pacchetto a tutti i suoi vicini. Quando un nodo riceve un pacchetto broadcast, duplica il pacchetto e lo invia a tutti i suoi vicini, eccetto quello da cui l'ha ricevuto. Se la rete ha una topologia a maglia una copia del pacchetto viene consegnata a tutti i nodi della rete. Ma la maglia potrebbe avere dei cicli, in cui il pacchetto verrebbe ripetuto indefinitamente. Ad esempio, nella figura precedente, R2 invia il pacchetto a diffusione, quindi a R3, R3 lo invia a R4, R4 a R2 e quindi si ripete il ciclo. Si viene a creare, cioè, una circolazione ciclica del pacchetto, una volta in senso orario, un'altra in senso antiorario. Ma ancora peggio, se un nodo è connesso a più di due nodi creerà ed invierà copie del pacchetto broadcast, ognuno dei quali crea copie multiple di sé stesso (ad altri nodi con più di due vicini), e così via. Ad un certo punto la proliferazione di pacchetti di broadcast potrebbe portare all'inutilizzo della rete.
Diffusione Controllata
Per evitare la proliferazione dei pacchetti broadcast, un nodo dovrebbe saper decidere quando diffondere un pacchetto, ad esempio, tenendo conto che quel pacchetto è stato già ricevuto. Ci sono diverse tecniche per risolvere questo problema.
Nel flooding con numero di sequenza controllato, un nodo sorgente inserisce il suo indirizzo (o un altro identificatore univoco) ed un numero di sequenza di broadcast nel pacchetto, e poi invia il pacchetto in broadcast ai suoi vicini. Ogni nodo mantiene una lista degli indirizzi sorgente e dei numeri di sequenza di tutti i pacchetti di broadcast che ha già ricevuto, duplicato e smistato. Quando un nodo riceve un pacchetto di broadcast, controlla prima se il pacchetto è presente nella lista. Se lo trova, lo scarta, se non lo trova lo duplica e lo invia ai suoi vicini, eccetto quello da cui l'ha ricevuto. Il protocollo Gnutella che svolge questa operazione, funziona a livello applicazione.
Un secondo approccio al flooding controllato è noto come reverse path forwarding (RPF) o anche reverse path broadcast (RPB). Quando un router riceve un pacchetto di broadcast con un certo indirizzo sorgente, trasmette il pacchetto su tutti i canali di uscita (eccetto quello di provenenza) solo se il pacchetto è arrivato sul canale che si trova sul cammino di costo minimo che lo porta alla sorgente. Altrimenti il router scarta il pacchetto. Un tale pacchetto può essere cancellato perchè il router sa che riceverà o ha già ricevuto una copia di questo pacchetto sul canale che si trova sul cammino ottimale che porta indietro fino al mittente. (Lo studioso lettore è invitato a convincersi che ciò avverrà e che non si verificherà la circolazione indefinita di pacchetti broadcast). Notare che RPF non usa il routing unicast per consegnare un pacchetto a una destinazione, e non richiede che un router conosca il percorso completo da sé stesso alla sorgente. RPF ha bisogno solo di sapere il prossimo vicino che si trova sul suo percorso più breve verso la sorgente. Usa l'identità del vicino solo per decidere se diffondere un pacchetto di broadcast ricevuto.
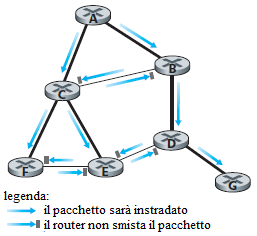
La figura illustra il funzionamento di RPF. Si supponga che il canale disegnato con linea spessa rappresenti il cammino di costo minimo dai ricevitori alla sogente A. Il nodo, inizialmente, invia in broadcast un pacchetto ai nodi C e B. Il nodo B invierà il pacchetto ricevuto da A (poichè A si trova sul cammino di costo minimo verso A) sia a C che a D. B ignorerà (scarta, senza ripetere) ogni pacchetto originato da A che riceverà da un qualsiasi altro nodo (ad esempio dal router C o dal router D). Adesso si consideri il nodo C, che ha ricevuto un pacchetto, originato da A, direttamente da A e da B. Poichè B non si trova sul cammino di costo minimo verso A, C ignorerà ogni pacchetto originato da A che riceverà da B. In altri termini, quando C riceve un pacchetto originato da A direttamente da A, lo smisterà ai nodi B, E ed F.
Spanning-Tree Broadcast
Le due tecniche viste, diffusione con controllo del numero di sequenza e RPF, evitano la circolazione indefinita di pacchetti di broadcast, non evitano completamente la circolazione di pacchetti di broadcast ridondanti. Ad esempio, nella figura precedente, i nodi B, C, D, E ed F ricevono uno o due pacchetti ridondanti. Si preferirebbe che ogni nodo riceva un solo pacchetto di broadcast. Osservando l'albero dei nodi connessi dalle linee spesse nella figura seguente:
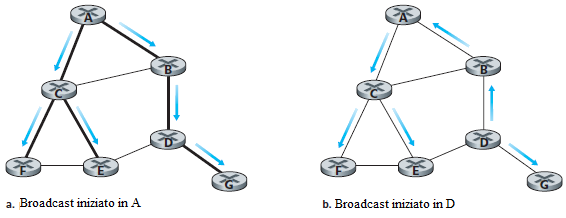
si vede che se i pacchetti di broadcast venissero instradati solo lungo i canali di questo albero, ciascun nodo della rete riceverebbe esattamente una sola copia del pacchetto di broadcast. Questo albero è stato ottenuto con l'algoritmo di spanning tree. Uno spanning tree di un grafo G = (N, E) è un grafo G' = (N, E') tale che E' è un sottoinsieme di E, G' è connesso, G' non contiene cicli e G' contiene tutti i nodi contenuti anche in G. Se ogni canale ha un costo e il costo dell'albero è la somma dei costi dei canali, allora uno spanning tree il cui costo è il minimo tra tutti i costi degli alberi di spanning tree che si possono estrarre dal grafo è detto lo spanning tree minimo.
Quindi un altro approccio al broadcast consiste nel far costruire, ad ogni nodo della rete, la topologia logica ad albero della rete. Quando un nodo sorgente deve inviare un pacchetto in broadcast, invia il pacchetto su tutti i canali che appartengono allo spanning tree. Un nodo che riceve un pacchetto di broadcast ripete il pacchetto a tutti i suoi vicini che appartengono allo spanning tree (eccetto quello da cui l'ha ricevuto). Lo spanning tree non elimina solo i pacchetti di broadcast ridondanti, ma ogni nodo può usare lo spanning tree per iniziare una comunicazione broadcast. Notare che un nodo non deve conoscere l'intero albero, gli basta sapere quale dei suoi vicini in G sono vicini nello spanning tree.
Uno degli algoritmi per ottenere lo spanning tree definisce un nodo centrale, verso cui tutti i nodi inviano i messaggi in unicast. Un messaggio viene inviato, usando il routing unicast, al nodo centrale fino a quando arriva ad un nodo che appartiene allo spanning tree oppure arriva al nodo centrale. In ogni caso, il cammino che il messaggio di ricongiungimento all'albero ha seguito individua il ramo dello spanning tree tra il nodo che ha originato il messaggio di ricongiungimento ed il centro.
Questo nuovo percorso può essere immaginato come un innesto sullo spanning tree esistente. Supporre che il nodo E sia selezionato come centro dell'albero. Supporre che il nodo F si collega all'albero ed invia ad F un messaggio di ricongiungimento all'albero. Il canale EF diventa lo spanning tree iniziale. Il nodo B poi congiunge lo spanning tree inviando il suo messaggio di ricongiungimento ad E. Si supponga che il cammino unicast da B verso E passi attraverso D. In questo caso, il messaggio di ricongiungiento all'albero risulta nel cammino BDE innestato sullo spanning tree. Il nodo A poi si congiunge al gruppo inviando ad E il suo messaggio di ricongiungimento all'albero. Se il percorso unicast da A verso E passa attraverso B, allora poichè B si è già congiunto allo spanning tree, l'arrivo del mesaggio di ricongiungimento di A a B risulterà in un ramo che si innesta immediatamente nello spanning tree. Il nodo C si congiunge allo spanning tree inviando il suo messaggio di ricongiungimento direttamente ad E. Infine, poichè il routing unicast da G ad E deve passare attraverso il nodo D, quando G invia il suo messaggio di ricongiungimento ad E, il canale GD viene innestato nello spanning tree al nodo D.
Gli algoritmi di Broadcast in Pratica
I protocolli di broadcast sono impiegati sia a livello applicazione, sia a livello rete. Il protocollo Gnutella usa il broadcast a livello applicazione per inviare messaggi agli altri processi dello stesso protocollo. Un canale tra due processi Gnutella è una connessione TCP. Il protocollo Gnutella usa una forma di diffusione controllata dai numeri di sequenza, in cui nei pacchetti ci sono un identificatore a 16 bit ed un campo dati a 16 bit (che identifica il tipo del messaggio) usati per rilevare se un pacchetto di broadcast ricevuto è stato già ricevuto in precedenza, duplicato e smistato. Gnutella usa anche un campo TTL per limitare il numero di hop da attraversare. Quando un processo Gnutella riceve e duplica un pacchetto, decrementa di uno il campo TTL prima di smistare il pacchetto. Quindi un pacchetto Gnutella raggiunge i nodi che distano TTL hop dalla sorgente.
Una forma di diffusione di pacchetti con il controllo dei numeri di sequenza è usata per inviare i messaggi di notifica LSP di OSPF. OSPF usa un numero di sequenza a 32 bit, ed un campo di 16 bit, in cui si mantiene l'età del pacchetto. Si ricordi che OSPF invia periodicamente, in broadcast i messaggi LSP sui suoi canali, oppure quando cambia il costo di un canale, o ancora quando un canale cambia stato (disponibile-non disponibile). I numeri di sequenza degli LSP servono a individuare i duplicati, ma anche per riconoscere l'ordine dei messaggi. Infatti, con il flooding, un pacchetto, generato al tempo t, potrebbe arrivare dopo un pacchetto più recente, generato dalla stessa sorgente al tempo t+d. I numeri di sequenza, usati da un nodo sorgente, consentono di distinguere un pacchetto vecchio da uno nuovo. Il campo "età" ha uno scopo simile al campo TTL. Il campo età viene posto, inizialmente, a 0, e viene incrementato di uno da ogni nodo che lo diffonde.
Multicast
Il servizio multicast consiste nel consegnare un pacchetto solo ad un sottoinsieme di nodi della rete. Questo servizio è richiesto da nuove applicazioni di rete che prevedono la consegna di pacchetti, generati da certi mittenti, solo ad un gruppo di destinatari. Tra queste applicazioni sono comprese quelle che trasferiscono grossi blocchi di dati (ad esempio aggiornamenti di software dal produttore agli utenti), lo streaming continuo (ad esempio la distribuzione di audio, video o testo ad un insieme di partecipanti), applicazioni di condivisione di dati (ad esempio la teleconferenza), distribuzione di dati (ad esempio quotazioni di borsa), giochi interattivi tra più partecipanti.
Nella comunicazione Multicast, sorgono subito due problemi. Come identificare i ricevitori di un pacchetto multicast e come indirizzare un pacchetto a questi ricevitori. Nel caso della comunicazione unicast, l'indirizzo IP del destinatario viene inserito in ogni datagramma e identifica il singolo ricevitore. nel caso del broadcast, tutti i nodi devono ricevere il datagramma, quindi non è necessario specificare l'indirizzo del destinatario. Nel caso del multicasting, essendoci più ricevitori, come si può specificare l'elenco dei destinatari? Se ci fossero pochi ricevitori, si potrebbe pensare di inserire i loro indirizzi IP nel pacchetto, ma con un numero elevato di destinatari, gli indirizzi da inserire potrebbero far raggiungere dimensioni intollerabili al pacchetto. Ma l'identificazione esplicita dei destinatari, richiede che il mittente conosca le loro identità e i loro indirizzi.
Per questi motivi, nell'architettura di Internet (e anche in altre, come ATM) un pacchetto multicast viene indirizzato usando un identificatore per un gruppo di ricevitori. Una copia del pacchetto che deve essere spedito a questo gruppo specifica l'identificatore del gruppo. In Internet, il singolo identificatore che rappresenta un gruppo di ricevitori è un indirizzo IP di classe D. Il gruppo di ricevitori associato con un indirizzo di classe D è detto gruppo di multicast.
La figura seguente mostra l'astrazione del gruppo di multicast.
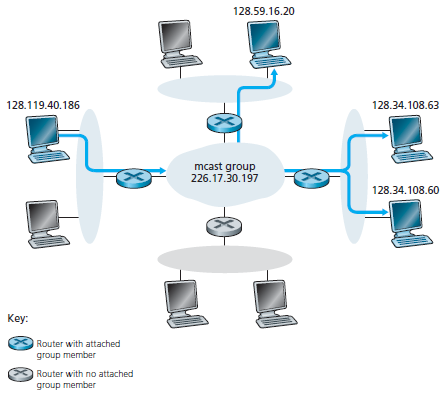
Nella figura ci sono quattro host associati all'indirizzo di gruppo multicast 226.17.30.197, che riceveranno tutti i datagrammi destinati all'indirizzo di multicast. La difficoltà da risolvere è che ogni host ha un proprio indirizzo IP di unicast, che è del tutto indipendente dall'indirizzo del gruppo di multicasting a cui appartiene. Come si crea e come si elimina un gruppo? Come si aggiungono nuovi host (come mittenti o come destinatari) al gruppo? Chiunque può diventare membro (come mittente o come destinatario) del gruppo oppure ci sono delle limitazioni? in questo caso chi autorizza l'ammissione al gruppo? I membri del gruppo conoscono le identità degli altri membri? Come cooperano i nodi della rete per consegnare un pacchetto multicast a tutti i membri del gruppo? Nell'architettura Internet, la risposta a queste domande è data dal protocollo Internet Group Management Protocol.
Internet Group Management Protocol
Il protocollo IGMP version 3 opera tra un host ed il router a cui è connesso direttamente (questo router collegato direttamente all'host è il router di primo hop che un host vede per raggiungere altri host esterni alla propria sottorerete, oppure può essere considerato come l'ultimo router che un pacchetto generato da un host esterno deve attraversare per raggiungere l'host).
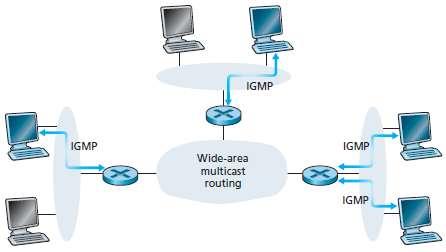
La figura mostra i router multicast di primo hop, ognuno connesso al suo host attraverso un'interfaccia locale. In questo esempio, questa interfaccia locale è collegata alla LAN, e mentre ogni LAN ha molti host, alcuni di questi host appartengono ad un gruppo di multicast, in un dato istante.
IGMP fornisce i mezzi per consentire ad un host di informare i router a cui è collegato che una applicazione in esecuzione su un host vuole congiungersi ad uno specifico gruppo multicast.
Poichè l'ambito di interazione di IGMP è limitato ad un host ed al router a cui è collegato, è richiesto un altro protocollo per coordinare i router multicast (compreso i router collegati) attraverso Internet, così che i datagrammi possano essere instradati verso la loro destinazione finale. Quest'ultima funzionalità è eseguita dagli algoritmi di instradamento di multicast a livello Rete. Il multicast a livello Rete in Internet, è composto da due componenti complementari: IGMP e i protocolli di routing multicast.
IGMP ha solo tre tipi di messaggi. Come ICMP, i messaggi IGMP sono portati (incapsulati) in un datagramma IP, con numero di protocollo 2. Il messaggio membership_query è inviato da un router a tutti gli host raggiungibili da una certa interfaccia (ad esempio a tutti gli host di una sottorete) per determinare l'insieme di tutti i gruppi multicast che sono stati congiunti dagli host su quell'interfaccia. Gli host rispondono ad un messaggio membership_query con un messaggio membership_report. Ma questo messaggio può essere anche generato da un host quando una applicazione si congiunge al gruppo multicast senza aspettare il messaggio membership_query dal router. L'ultimo tipo di messaggio IGMP è il messaggio leave_group. Questo messaggio è facoltativo. Ma se è facoltativo, come fa un router a riconoscere quando un host si separa dal gruppo multicast? Il router deduce che un host non appartiene più al gruppo multicast se non risponde più al messaggio membership_query contenente l'indirizzo del gruppo. Questo è un esempio di quello che in un protocollo Internet viene chiamato stato soft. Uno stato soft in un protocollo Internet, lo stato (in questo caso di IGMP, il fatto che ci sono host uniti in un dato gruppo multicast) viene rimosso tramite un evento timeout (in questo caso, tramite un messaggio periodico membership_query del router. se non è esplicitamente riconfermato (in questo caso, tramite un messaggio membership_report inviato dall'host).
algoritmi di instradamento Multicast
Il problema dell'instradamento Multicast è illustrato nella figura seguente:
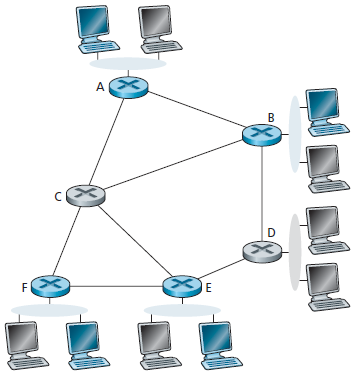
Gli host riuniti in un gruppo multicast, ed i router a cui sono collegati, sono colorati. Solo un sottoinsieme dei router (quelli con host che appartengono ad un gruppo multicast) hanno bisogmo di ricevere traffico multicast. In figura, solo i router A, B, E, ed F hanno bisogno di ricevere il traffico multicast. Poichè nessuno degli host collegati al router D appartiene al gruppo multicast e poichè il router C non ha host, né C né D hanno bisogno di ricevere il traffico del gruppo multicast. Lo scopo del routing multicast, è di trovare un albero di canali che connetta tutti i router che hanno host appartenenti al gruppo multicast. I pacchetti Multicast saranno instradati lungo questo albero dal mittente a tutti gli host che appartengono all'albero multicast. Naturalmente, l'albero può contenere router che collegano host che non appartengono al gruppo multicast (ad esempio, nella figura, è impossibile connettere i router A, B, E, ed F in un albero senza coinvolgere i router C o D).
Nella pratica, sono stati adottati due approcci per determinare l'albero di routing multicast, questi sono gli stessi che si usano nell'instradamento broadcast. I due approcci differiscono a seconda se un singolo albero di un gruppo condiviso è usato per distribuire il traffico di tutti i mittenti nel gruppo oppure se l'albero di instradamento con una sola sorgente, viene costruito per ogni singolo mittente.
Instradamento Multicast che usa un albero di un gruppo condiviso. Come nel caso del broadcast sullo spanning-tree, il routing multicast su un albero di un gruppo condiviso consiste nella costruzione di un albero che include tutti i router di frontiera che hanno degli host collegati, che appartengono al gruppo multicast. In pratica, si usa un approccio basato su un router centralizzato per costruire l'albero di instradamento multicast, con i router di frontiera degli host appartententi al gruppo multicast, inviando (in unicast) messaggi di ricongiungimento indirizzati al nodo centrale. Come nel caso del broadcast, un messaggio di ricongiungimento viene smistato, usando il routing unicast, verso il centro fino a quando arriva ad un router che appartiene all'albero multicast o arriva al centro. Tutti i router, lungo il percorso che il mesaggio di ricongiungimento segue, instraderanno i pacchetti multicast ricevuti al router di frontiera da cui è iniziato il ricongiungimenti multicast. Il problema di questo algoritmo riguarda il criterio per selezionare il nodo centrale.
Instradamento Multicast usando un albero basato sulla sorgente. Mentre l'algoritmo di multicast con un albero condiviso costruisce un solo albero di instradamento per smistare i pacchetti da tutti i mittenti, il secondo approccio costruisce un albero di instradamento multicast per ogni sorgente del gruppo multicast. In pratica, un algoritmo RPF (con un nodo sorgente x) è usato per costruire un albero di instradamento multicast per i datagrammi multicast generati dalla sorgente x. Si consideri il router D nella figura seguente:
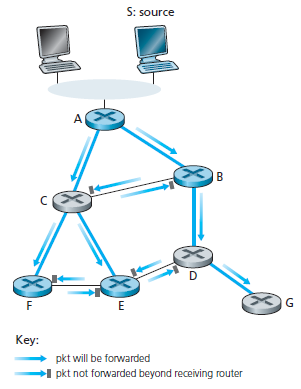
Nel broadcast RPF, si dovrebbero instradare pacchetti al router G, persino se il router G non ha host che appartengono al gruppo multicast. Anche se questo non è un grave problema per questo caso dove D ha soltanto il router D a valle, immaginare cosa accadrebbe se ci fossero migliaia di router a valle di D. Ognuno di queste migliaia di router riceveranno pacchetti multicast indesiderati. La soluzione al problema di ricevere pacchetti multicast indesiderati sotto RPF è noto come la potatura. Un router multicast che riceve pacchetti multicast e non ha host collegati uniti a quel gruppo invierà un messaggio di potatura al suo router a monte. Se un router riceve messaggi di potatura da ciascuno dei suoi router a valle, allora può inoltrare un messaggio di potatura a monte.
Instradamento Multicast in Internet
Il primo protocollo di instradamento multicast usato in Internet fu il Distance-Vector Multicast Routing Protocol (DVMRP). Il DVMRP implementa alberi, la cui radice è un router sorgente, con l'instradamento a ritroso e la potatura. Il DVMRP usa un algoritmo RPF con potatura. Forse il più diffuso protocollo di instradamento multicast in Internet è il Protocol-Independent Multicast (PIM), che riconosce esplicitamente due scenari di instradamento multicast distribuiti. Nella modalità "dense", i membri del gruppo multicast sono localizzati densamente; cioè, molti dei router nell'area hanno bisogno di essere coinvolti nel routing multicast dei datagrammi. la modalità dense del PIM è una tecnica di instradamento a ritroso con diffusione e potatura simile a DVMRP. Nella modalità sparsa, il numero dei router con membri del gruppo collegati è piccolo rispetto al numero totale dei router; i membri del gruppo sono dispersi geograficamente. La modalità sparsa del PIM riunisce due punti per impostare l'albero di distribuzione multicast. Nel multicast con sorgente specifica (SSM), solo un singolo mittente è autorizzato ad inviare traffico nell'albero multicast, semplificando notevolmente la costruzione e la manutenzione dell'albero.
Quando il PIM e il DVMP sonmo usati in un dominio, l'operatore della rete può configurare L'IP dei router multicast entro il dominio, nello stesso modo dei protocolli unicast come il RIP, IS-IS, ed OSPF. Ma cosa succede quando i router multicast sono necessari tra diversi domini? C'è un multicast equivalente del protocollo inter-domain BGP? La risposta è sì. Le estensioni del protocollo di BGP consentono di trasportare informazioni di instradamento per altri protocolli, incluso le informazioni multicast. Il Multicast Source Discovery Protocol (MSDP) può essere usato per connettere punti di raccolta in differenti domini PIM sparsi.