Il protocollo IP.
Indirizzamento in Internet
In questa sezione si esaminerà come avviene l'instradamento e come si assegnano gli indirizzi agli host. L'instradamento e l'indirizzamento sono due componenti del protocollo IP. Esistono due versioni del protocollo IP. La più diffusa è la IPv4. Questa versione verrà sostituita dal protocollo IPv6.
I principali componenti del livello Rete di Internet sono il protocollo IP, le apparecchiature di instradamento (che determinano il percorso che i pacchetti devono seguire per andare da una sorgente verso una destinazione), il terzo componente è l'Internet Control Message Protocol (ICMP), che è utile per eseguire una diagnostica della rete.
Formato del datagramma IP
| bit | 0 | 32 | ||||
| header IP - | versione | Lunghezza Header |
Tipo di servizio |
Lunghezza pacchetto | ||
| ID | flag | offset frammento | ||||
| Time To Live | protollo del livello superiore |
header checksum | ||||
| indirizzo IP sorgente | ||||||
| indirizzo IP destinazione | ||||||
| Opzioni IP | Padding | |||||
| payload - | … Dati … | |||||
Un pacchetto del livello Rete è chiamato datagramma. Il suo formato è mostrato nella figura. Il significato dei campi è il seguente:
Numero di versione. Questi 4 bit specificano il numero della versione del datagramma. Osservando questo numero il router stabilisce come interpretare il resto del pacchetto. Il formato del datagramma per la versione IP attuale, IPv4, è mostrato nella figura. Il formato per la versione IPv6 verrà illustrato più avanti in questa sezione.
Lunghezza Header. L'intestazione di un datagramma IPv4 può contenere alcuni campi facoltativi, questo valore consente di determinare la posizione da cui iniziano i dati. Tipicamente l'header di un datagramma IP, senza i campi facoltativi, è composta di 20 byte.
Tipo di servizio. Lo scopo di questo campo è quello di distinguere i diversi tipi di datagramma. I servizi che si potrebbero richiedere, ad esempio, sono un tempo massimo di consegna, oppure si potrebbe desiderare che i pacchetti si susseguando con una distanza regolare. Potrebbe servire per riconoscere i datagrammi per i quali è richiesto un servizio real-time, come quelli usati dalle applicazioni di telefonia su IP, da quelli che non ne hanno bisogno (ad esempio FTP).
Lunghezza del pacchetto. Il valore di questo campo indica il numero di byte totali del pacchetto (header+dati). Poiché questo campo è lungo 16 bit, la dimensione massima di un datagramma è di 65.536 byte. Nella pratica i datagrammi sono lunghi solo 1500 byte.
Identificatore, flag e offset del frammento. Questi tre campi sono associati alla scomposizione di un pacchetto molto grande in più parti.
Time To Live. Questo campo è usato per prevenire la circolazione all'infinito di un datagramma che non riesce ad uscire da un percorso ciclico, causato dall'interruzione della linea che lo porterebbe a destinazione. Ogni router che riceve il datagramma decrementa questo valore di 1 e il router che riceve il datagramma con TTL=0 non ripete più il pacchetto.
Protocollo. Il codice del protocollo serve solo al livello rete dell'host destinazione. Il suo valore indica il protocollo del livello superiore a cui deve essere consegnato il messaggio contenuto nel datagramma. Ad esempio il valore 6 indica che i dati devono essere consegnati al TCP, mentre il valore 17 indica che i dati devono essere consegnati all'UDP. Si noti che il numero del protocollo ha un significato analogo al numero di porta usato a livello Trasporto. Il codice del protocollo specifica a quale protocollo del livello Trasporto il livello Rete sta offrendo il servizio, mentre il numero di porta indica a quale processo applicativo il livello Trasporto sta offrendo il servizio. Naturalmente anche il frame di livello 2 ha una indicazione per specificare a quale processo del livello Rete offre il servizio.
Header Checksum. Il campo Checksum serve al router per riconoscere un pacchetto che è stato modificato dal rumore presente sul canale. Il calcolo del Checksum consiste nel considerare l'header come un insieme di numeri di 2 byte. Il valore che viene inserito nel campo Checksum è il complemento a 1 della somma di questi numeri. Ogni router che riceve il pacchetto ricalcola il Checksum e lo confronta con quello presente nell'header del datagramma. Se il Checksum ricalcolato non corrisponde al Checksum ricevuto, il router scarta il pacchetto. Il controllo degli errori è eseguito anche a livello Trasporto. La differenza è che il livello Rete calcola il Checksum solo sull'header, mentre il livello Trasporto calcola il Checksum sull'intero segmento. Anche se il controllo degli errori è un compito del livello 2, il TCP applica lo stesso controllo, perché non può essere sicuro che il pacchetto attraversi router sui quali è implementato un livello Rete non conforme all'architettura TCP/IP.
Indirizzo Sorgente e Indirizzo Destinazione. L'host sorgente che crea un datagramma deve inserire in questi due campi il suo indirizzo IP nel campo sorgente e l'indirizzo IP dell'host ricevitore nel campo indirizzo destinazione. Per conoscere l'indirizzo IP del destinatario, l'host sorgente usa il protocollo DNS.
Opzioni. I campi Opzioni hanno lo scopo di mantenere basse le dimensioni di un datagramma IP, ma di prevedere la possibilità di aggiungere altre informazioni solo quando è necessario. La presenza di questi campi opzionali nell'header di un datagramma, costringe ad usare il campo "Header Length" per indicare dove termina l'intestazione e quindi dove iniziano i dati. Inoltre la presenza o l'assenza dei campi Opzioni provoca un diverso tempo di elaborazione di un datagramma da parte dei router. Per queste ed altre ragioni, il campo Opzioni è stato eliminato dai datagrammi IPv6.
Dati. Il campo Dati del datagramma IP contiene segmenti del livello Trasporto. Potrebbe anche contenere informazioni del protocollo ICMP. Un datagramma IP porta 20 byte riservati all'header (se non ci sono Opzioni). Se il datagramma IP contiene un segmento TCP allora il datagramma porta altri 20 byte di header del segmento e quindi, in totale, contiene 40 byte per l'header, oltre ai dati da consegnare al processo applicativo.
Frammentazione dei datagrammi IP
Non tutti i protocolli di livello collegamento (livello 2) accettano pacchetti dal livello Rete di lunghezza arbitraria. Alcuni gestiscono pacchetti di qualsiasi dimensione, altri protocolli accettano solo pacchetti piccoli. Ad esempio le trame Ethernet possono contenere al massimo 1500 byte di dati, mentre altri protocolli ammettono solo 576 byte di dati. La massima quantità di dati che una trama di livello collegamento può portare è chiamata Maximum Transmission Unit (MTU). Poiché ogni datagramma IP, quando viaggia da un router all'altro, è incapsulato in una trama di livello Collegamento, la MTU del livello Collegamento impone una forte limitazione alla lunghezza di un datagramma IP. Ma il problema è che ognuno dei canali lungo il percorso tra mittente e destinatario può usare protocolli di livello Collegamento differenti, ed ognuno di questi protocolli ha una diversa MTU.
Si immagini che un router possa ricevere, dai suoi vicini, datagrammi con protocolli del livello Collegamento diversi. Se si riceve un datagramma IP su un canale, potrebbe succedere che la linea di uscita su cui lo si deve ripetere, richiede una MTU minore della lunghezza del datagramma. Il router, prima di spedire il pacchetto frammenta il campo dati contenuto nel datagramma IP ottenendo datagrammi IP più piccoli, incapsula ognuno di questi datagrammi IP in trame di livello Collegamento e invia queste trame sul canale di uscita. Questa operazione è detta frammentazione.
I frammenti dovranno essere riassemblati prima di raggiungere il livello Trasporto del destinatario. Sia TCP che UDP si aspettano di ricevere segmenti completi, non frammentati dal livello Rete. Il riassemblaggio dei pacchetti in un router inciderebbe sulle prestazioni e complicherebbe il protocollo, di conseguenza il riassemblaggio dei pacchetti è affidato al livello Rete del sistema terminale piuttosto che ai router della rete. Quando un host riceve una serie di datagrammi dalla stessa sorgente, determina se questi sono frammenti di un unico datagramma più grande. Se si trova che alcuni datagrammi sono frammenti si deve ancora determinare quando si è ricevuto l'ultimo e qual è il loro ordine. Nell'header del datagramma IP è presente un campo "flag" e un campo "offset del frammento". Quando un host sorgente crea un datagramma, oltre ad inserire gli indirizzi sorgente e destinazione, inserisce un numero di identificazione per ogni datagramma che spedisce. Per ogni datagramma inviato, l'host mittente incrementa questo numero. Quando un router è costretto a frammentare un datagramma, ripete questi campi in ogni frammento. L'host destinazione che riceve questi datagrammi dallo stesso mittente, legge i numeri di identificazione dei datagrammi per riconoscere quelli che fanno parte dello stesso datagramma originale. Poiché il livello Rete offre un servizio non affidabile, uno o più datagrammi potrebbero non arrivare mai a destinazione. Per consentire all'host destinazione di riconoscere l'ultimo datagramma del datagramma originale, il campo flag dell'ultimo datagramma porta il valore 0, mentre tutti i frammenti portano il valore 1. Inoltre il destinatario può verificare se manca un pacchetto (e determinare l'ordine dei pacchetti da riassemblare) osservando il valore progressivo nel campo offset dell'header del datagramma.
Esempio: un datagramma lungo 4000 byte (20 byte per l'header e 3980 byte per i dati) giunto in un router deve essere inviato verso un altro router avente MTU=1500 byte. I 3980 byte devono essere suddivisi in tre frammenti e, ciascuno di essi, deve essere incapsulato in un datagramma. La figura seguente descrive i campi e i valori usati nell'header dei frammenti, assumendo che il datagramma originale aveva il numero di identificazione = 777:
| Frammento | Nr. Byte | ID | Offset | Flag |
| Primo | 1.480 byte nel campo dati | identificazione=777 | offset 0 significa che il primo byte è il numero 0 | 1 significa che ce ne sono altri |
| Secondo | 1.480 byte nel campo dati | identificazione=777 | offset 185 significa che il primo byte è il numero 8·185=1480 | 1 significa che ce ne sono altri |
| Terzo | 1.020 byte (=3980-1480-1480) | identificazione=777 | offset 370 significa che il primo byte è il numero 2960 (=370·8) | 0 significa che è l'ultimo |
Notare che il numero di offset è specificato come numero d'ordine del primo byte all'interno dei dati del datagramma originale ed ogni unità indica un blocco di 8 byte.
Alla destinazione i dati del datagramma vengono consegnati al livello Trasporto solo dopo che il livello Rete ha ricostruito il datagramma IP originale. Se uno o più frammenti non arriva a destinazione, tutto il datagramma originale viene scartato. Sarà compito del TCP recuperare questo segmento perso.
La frammentazione ha dei costi. Primo, i router e i sistemi terminali devono essere in grado di frammentare e riassemblare i datagrammi. Secondo, la frammentazione può essere usata per realizzare attacchi DoS, consistente nell'invio di frammenti contenenti numeri di offset casuali. Ad esempio l'attaccante invia un flusso di piccoli pacchetti all'host vittima, in nessuno dei quali il campo offset ha valore 0, e il destinatario resta impegnato a ricostruire datagrammi inesistenti. Un altro tipo di attacco consiste nell'inviare datagrammi con valori nel campo offset che si sovrappongono e che quindi il sistema operativo del destinatario non sa come trattare. Il protocollo IPv6 risolve questi rischi.
Indirizzi IPv4
Un host, in genere, ha solo un canale di collegamento alla rete. Quando il livello Rete (IP) dell'host deve spedire un datagramma, lo invia su questo canale. L'host possiede una interfaccia per collegarsi al canale fisico. Poiché un router ha il compito di smistare i pacchetti ricevuti su una interfaccia verso l'interfaccia di uscita, anche un router possiede una interfaccia per ogni canale fisico. Di conseguenza ogni interfaccia deve avere un proprio indirizzo IP. L'indirizzo IP identifica l'interfaccia, non l'host o il router che possiede quella interfaccia.
Un indirizzo IP è lungo 32 bit (4 byte), quindi si possono formare 232 indirizzi IP, poco più di 4 miliardi di indirizzi.
Questi indirizzi vengono espressi scrivendo ciascun byte nella forma decimale e separandoli con un punto. Ad esempio nell'indirizzo 193.32.216.9, il valore 193 corrisponde alla rappresentazione in decimale del primo byte dell'indirizzo IP, il valore 32 corrisponde alla rappresentazione in decimale del secondo byte, e così via. La notazione in binario dell'indirizzo 193.32.216.9 è:
11000001 00100000 11011000 00001001
In Internet ogni interfaccia di un host e di un router deve avere un indirizzo IP univoco. Questi indirizzi non possono essere scelti liberamente. Una parte dell'indirizzo IP è determinata dalla sottorete a cui è connessa l'interfaccia.
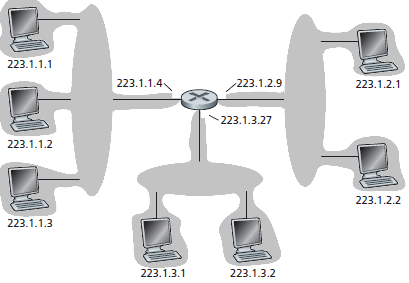
La figura riporta un esempio di indirizzamento IP. Un router possiede tre interfacce per interconnettere sette host. I tre host in alto a sinistra e l'interfaccia a cui si connettono hanno l'indirizzo IP della forma 223.1.1.x. Cioè hanno in comune i primi 24 bit dell'indirizzo IP. Le quattro interfacce, di questa sottorete, sono interconnesse da una rete che non contiene router. Potrebbe essere una LAN Ethernet, in cui le stazioni sono collegate ad un switch, o una rete wireless in cui le stazioni si collegano ad un access point.
Nella terminologia IP le interfacce di questi host e l'interfaccia del router, a cui gli host sono collegati, è detta subnet (sottorete).
L'indirizzo di questa subnet viene indicato come: 223.1.1.0/24, in cui la notazione /24 nota come subnet mask, specifica che i 24 bit più a sinistra dell'indirizzo costituiscono l'indirizzo della subnet. La subnet 223.1.1.0/24 consiste delle tre interfacce degli host (223.1.1.1, 223.1.1.2 e 223.1.1.3) e dell'interfaccia del router (223.1.1.4). Ogni successivo host che si aggiungerà alla sottorete 223.1.1.0/24 deve avere un indirizzo della forma 223.1.1.xxx, cioè deve avere lo stesso prefisso di 24 bit. Nella figura ci sono altre due sottoreti. la subnet 223.1.2.0/24 e la subnet 223.1.3.0/24.
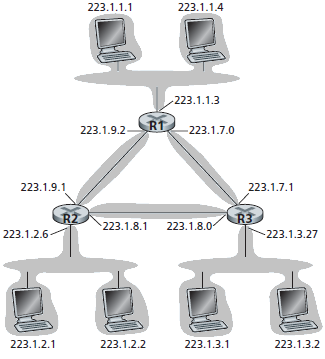
La definizione di sottorete non si applica solo al caso di una LAN Ethernet collegata sulle interfacce del router. La figura seguente mostra tre router collegati tra loro. Ogni router ha tre interfacce, due per connettersi agli altri due router ed un canale broadcast (cioè una rete con topologia a bus o con topologia a stella il cui centro stella è un HUB) per connettersi agli host di una LAN. Ci sono tre subnet (223.1.1.0/24, 223.1.2.0/24, e 223.1.3.0/24) in cui sono ospitati gli host, ed altre subnet: la subnet 223.1.9.0/24, per il collegamento delle interfacce dei router R1 ed R2, la subnet 223.1.8.0/24, per il collegamento delle interfacce dei router R2 ed R3, e la subnet 223.1.7.0/24, per il collegamento delle interfacce dei router R1 ed R3. La regola per definire le sottoreti può essere così definita:
Le sottoreti sono formate da tutte le interfacce che hanno lo stesso punto di terminazione, attraverso il quale si passa ad un altro insieme di interfacce.
Una organizzazione preferisce ripartire la sua rete in più segmenti Ethernet.
Lo schema di assegnazione degli indirizzi IP in Internet è detto Classless Interdomain Routing (CIDR). Le regole CIDR generalizzano il concetto di indirizzo di subnet. Un indirizzo IP di 32 bit è diviso in due parti (il prefisso di rete e il numero di host). Con la notazione A.B.C.D/x si specifica che x bit, nella parte di sinistra dell'indirizzo IP rappresentano il prefisso della rete e il numero della sottorete.
Un'organizzazione che chiede ad un provider l'assegnazione di un indirizzo IP, in genere ottiene un intervallo di indirizzi contigui. Tutti i dispositivi interni alla rete avranno la stessa parte iniziale dell'indirizzo IP. Questo significa che quando un router esterno alla rete invia un datagramma il cui indirizzo destinazione è interno alla rete dell'organizzazione, prende in considerazione solo i primi x bit dell'indirizzo IP. In questo modo la dimensione della tabella di instradamento è molto più contenuta rispetto al caso in cui si memorizzerebbero gli indirizzi di tutte le interfacce. Nella tabella di instradamento basta specificare una riga che indica qual è l'interfaccia a cui consegnare un pacchetto destinato ad un host interno alla rete A.B.C.D/x
I rimanenti 32-x bit di un indirizzo vengono assegnati alle interfacce dei dispositivi interni all'organizzazione, cioè a tutte le interfacce che hanno lo stesso prefisso di rete. Questi bit saranno presi in considerazione quando si inviano pacchetti ai router interni alla rete. I bit di ordine inferiore dell'indirizzo IP, quelli che non fanno parte del prefisso di rete, potrebbero (o non) essere ulteriormente organizzati per individuare ancora altre sottoreti. Ad esempio, se i primi 21 bit dell'indirizzo A.B.C.D/21 specificano il prefisso della rete dell'organizzazione, e sono comuni agli indirizzi IP delle interfacce di tutti i dispositivi interni alla rete dell'organizzazione, i restanti 11 bit sono usati per identificare l'interfaccia degli host interni a quella sottorete. La struttura interna della rete potrebbe essere suddivisa in sottoreti, quindi gli 11 bit più a destra dell'indirizzo IP devono essere ulteriormente scomposti per riservare un certo numero di bit al numero di sottorete, ad esempio A.B.C.D/24 potrebbe specificare un indirizzo di sottorete.
Lo schema CIDR è stato introdotto per superare le limitazioni imposte dal vecchio schema di indirizzamento IP basato sulla suddivisione in classi. La classi riservavano 8, 16 o 24 bit per il prefisso di rete e, con la crescita di Internet, si sono rivelate insufficienti a soddisfare le esigenze di assegnazione di nuovi indirizzi. Inoltre c'era uno spreco di indirizzi, perché non tutto l'intervallo di indirizzi assegnato veniva utilizzato da una organizzazione. In una rete di classe C (/24) si potevano usare solo 28-2 = 254 indirizzi (due sono riservati). In una rete di classe B (/16) si potevano usare 216-2 =65.534 indirizzi, che sono troppi. Infatti se la rete conteneva, ad esempio, 2000 host restavano circa 63.000 indirizzi inutilizzati, che non potevano essere assegnati a nessun'altra organizzazione.
Ci sono due indirizzi riservati, che l'organizzazione non può assegnare a nessuna interfaccia di rete. Il primo indirizzo contiene tutti i bit a zero nel campo che identifica l'interfaccia (questo campo è detto anche numero di host). Questo indirizzo, infatti, è l'indirizzo della sottorete. L'altro indirizzo riservato contiene tutti i bit a livello 1 nel campo di identificazione dell'interfaccia e rappresenta un indirizzo di broadcast, cioè il pacchetto viene consegnato a tutti gli host della sottorete.
Un'organizzazione deve ottenere un blocco di indirizzi da assegnare ai suoi dispositivi, da questo blocco deve decidere come assegnare gli indirizzi ai dispositivi.
Ottenere un blocco di indirizzi
Per ottenere un blocco di indirizzi IP da assegnare agli host delle sottoreti di una organizzazione, l'amministratore della rete deve rivolgersi al suo provider e acquistare uno dei blocchi di indirizzi di cui il provider dispone. Ad esempio, un ISP dispone del blocco di indirizzi 200.23.16.0/20, e decide di suddividerlo in 8 blocchi di indirizzi contigui, allo scopo di assegnare ciascun blocco ad una di 8 organizzazioni che ne fanno richiesta, come mostrato di seguito (la parte prefisso di rete è sottolineata):
| NET-ID | Host ID | |||
| Blocco in possesso dell'ISP: | 200.23.16.0/20 | 11001000 00010111 0001 | 0000 00000000 | |
| NET-ID | Nr subnet | Nr host | ||
| Organizzazione 0: | 200.23.16.0/23 | 11001000 00010111 0001 | 000 | 0 00000000 |
| Organizzazione 1: | 200.23.18.0/23 | 11001000 00010111 0001 | 001 | 0 00000000 |
| Organizzazione 2: | 200.23.20.0/23 | 11001000 00010111 0001 | 010 | 0 00000000 |
| … | … | … | … | … |
| Organizzazione 7: | 200.23.30.0/23 | 11001000 00010111 0001 | 111 | 0 00000000 |
Il blocco di indirizzi al provider è stato concesso dall'Internet Corporation for Assigned Names and Numbers (ICANN), una autorità internazionale che gestisce gli indirizzi IP e i server DNS. Infatti, l'ICANN mantiene un registro per rispettare il requisito che ogni indirizzo IP di una macchina collegata alla rete sia univoco. L'ICANN deve garantire che anche i nomi di dominio siano univoci. A sua volta, l'ICANN distribuisce blocchi di indirizzi a gestori locali, che li assegnano a che ne fa richiesta, nelle regioni di loro competenza.
Ottenere un indirizzo per un Host: Dynamic Host Configuration Protocol
Dopo aver ottenuto un blocco di indirizzi dal provider, l'amministratore della rete deve assegnare un indirizzo IP alle interfacce degli host e dei router della rete. Nei router, questa operazione può essere fatta manualmente (anche nei router remoti, per mezzo di strumenti di gestione della rete), ma gli host possono essere configurati, oltre che manualmente, anche con il DHCP (Dynamic Host Configuration Protocol). Il server DHCP assegna automaticamente gli indirizzi agli host che si collegano alla rete. Un amministratore di rete configura il DHCP in modo che un dato host riceva lo stesso indirizzo IP ogni volta che si collega ad una rete oppure un indirizzo temporaneo, che quindi varia ogni volta che l'host si collega alla rete. Il DHCP, oltre ad assegnare l'indirizzo IP, fornisce anche altre informazioni all'host, ad esempio la subnet mask, l'indirizzo IP del router (anche detto gateway di default) che gli consente di collegarsi a Internet, e l'indirizzo del server DNS.
Un amministratore di rete preferisce usare un server DHCP, perché evita di inserire manualmente queste informazioni in ogni host della rete. Il DHCP è usato anche quando un host si collega a Internet o a una rete wireless.
Ad esempio un computer portatile ha bisogno di un nuovo indirizzo IP ogni volta che tenta di accedere a Internet da una nuova posizione, dove incontra una nuova sottorete. Il DHCP è la soluzione che consente di assegnare indirizzi IP a utenti che si connettono e disconnettono frequentemente, e l'uso di un indirizzo per l'accesso è richiesto per un durata di tempo limitata.
Il DHCP non è usato solo da un amministratore per la sua rete locale, ma anche da un provider per i suoi utenti. Infatti, se un ISP ha 2000 utenti, ma sa che solo 400 utenti si collegano contemporaneamente, anziché usare un blocco di 2048 indirizzi, per mezzo di un server DHCP assegna, dinamicamente, solo 512 indirizzi (ad esempio con un blocco A.B.C.D/23). Ogni volta che un host si collega, il server DHCP assegna uno degli indirizzi liberi, ogni volta che un host si disconnette l'indirizzo che gli era stato assegnato viene inserito dal DHCP nella lista degli indirizzi disponibili
Il DHCP è un protocollo client-server. Il client è il nuovo host che, per connettersi alla sottorete, chiede le informazioni di configurazione, compreso un indirizzo IP per la sua interfaccia. Nel caso più semplice, ogni sottorete deve avere il server DHCP. Se questo non è presente nella sottorete, il router deve essere istruito circa la raggiungibilità del server DHCP per la rete.
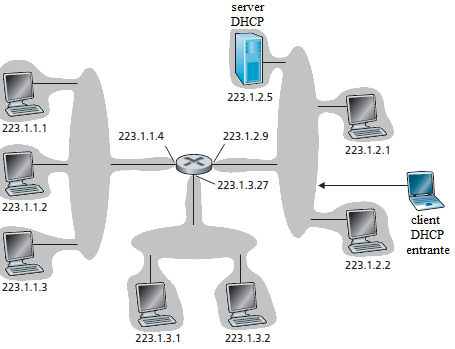
Nella figura il server DHCP è collegato alla sottorete 223.1.2.0/24, nella quale il router agisce come centro di smistamento per i pacchetti che giungono dalle sottoreti 223.1.1.0/24 e 223.1.3.0/24.
Per un nuovo host che chiede di inserirsi nella rete, il protocollo DHCP svolge 4 fasi
Scoperta del server DHCP. Un nuovo host che vuole collegarsi alla rete cerca un server DHCP con cui interagire. Per questa operazione il client invia un messaggio UDP verso la porta 67. Il pacchetto UDP viene incapsulato in un pacchetto di livello 3. Ma il client non può conoscere l'indirizzo IP della rete a cui vuole collegarsi, ancor meno conosce l'indirizzo IP del server DHCP di questa rete. Quindi il pacchetto creato dal client DHCP è di tipo broadcast e deve specificare l'indirizzo destinazione 255.255.255.255 e l'indirizzo sorgente 0.0.0.0. Il client DHCP passa il datagramma IP al livello Collegamento, che invia questo pacchetto a tutti i nodi della rete.
Proposte del server DHCP. Un server DHCP che riceve un messaggio di scoperta invia una risposta al client contenente un messaggio di offerta, anch'esso con l'indirizzo IP di tipo broadcast 255.255.255.255. La ragione per cui questo messaggio di risposta è destinato a tutti gli host sulla rete è che ci potrebbero essere diversi server DHCP sulla sottorete, il client può trovarsi a dover scegliere tra varie offerte. In ognuno dei messaggi di offerta che giungono al client, ci sono: il campo ID nell'header del pacchetto di offerta uguale al valore presente nel pacchetto di scoperta, l'indirizzo IP proposto al client, la subnet mask e la durata di validità dell'indirizzo IP.
Richiesta DHCP. Il nuovo client sceglie tra una o più offerte e invia un messaggio di richiesta al DHCP in cui sono ripetuti i parametri di configurazione.
Conferma DHCP. Il server risponde al messaggio di richiesta DHCP con un messaggio di conferma (ACK), che significa che i parametri sono stati accettati.
Il messaggio di conferma (DHCP ACK) conclude l'interazione, e il client può usare l'indirizzo IP che gli è assegnato per la durata di tempo in cui resta valido. Poiché un client potrebbe avere bisogno di usare l'indirizzo IP che gli è stato assegnato anche dopo la scadenza, il DHCP fornisce un meccanismo che consente di rinnovare l'indirizzo IP
In definitiva il server DHCP solleva l'amministratore dall'onere di assegnare manualmente gli indirizzi IP agli host della rete, in particolare agli host mobili. Poiché ogni nuovo dispositivo che si collega alla rete ottiene un nuovo indirizzo, se l'host si sposta tra le sottoreti non è possibile mantenere una connessione TCP. Questo invece è previsto per le reti wireless, che sono progettate per utenti mobili. Una recente versione del protocollo delle reti senza fili, nella configurazione ad infrastruttura, permette ad un dispositivo mobile di mantenere lo stesso indirizzo IP mentre si sposta tra le sottoreti.
Network Address Translation (NAT)
Come regola: ogni interfaccia di rete di un dispositivo deve possedere un indirizzo IP. La proliferazione di reti domestiche e di ufficio comporta che, per ogni sottorete contenente più macchine, l'ISP deve assegnare un intervallo di indirizzi sufficiente per soddisfare tutte le richieste di connessione. Se la sottorete cresce ancora, ad esempio per la presenza di smartphone, tablet e altri dispositivi, è necessario allargare l'intervallo degli indirizzi. Si corre il rischio che il provider non ne disponga in quantità sufficiente.
Nella figura seguente, il router abilitato ad eseguire il NAT (network address translation) ha una interfaccia dal lato della sottorete domestica. L'indirizzo della sottorete è 10.0.0.0/24. Lo spazio di indirizzi 10.0.0.0/8 è uno dei tre spazi di indirizzi privati. Un intervallo di indirizzi privati ha lo scopo di assegnare gli indirizzi alle interfacce di una rete domestica o di un piccolo ufficio.
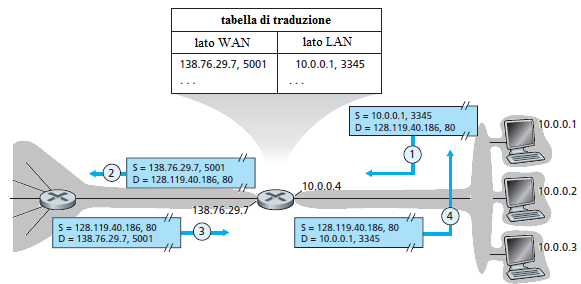
Per comprendere l'importanza degli indirizzi privati, si supponga di avere centinaia di migliaia di reti domestiche, molte delle quali usano lo stesso spazio di indirizzi 10.0.0.0/24. I dispositivi interni di una rete domestica possono scambiarsi pacchetti usando lo spazio di indirizzi 10.0.0.0/24. I pacchetti che dalla rete domestica passano sulla rete Internet non possono usare questi indirizzi nè come indirizzi sorgenti nè come indirizzi destinazione perché non sono univoci. Questi indirizzi privati hanno significato solo all'interno di una rete.
Il router su cui è abilitato il NAT è diverso dai router della rete geografica. Per i router della rete geografica, il router su cui viene eseguito il NAT si presenta come un dispositivo avente un solo indirizzo IP. Nella figura, ogni pacchetto del traffico che esce dal router della rete domestica ed entra nella rete Internet reca nel campo indirizzo sorgente dell'header il valore 138.76.29.7, e tutto il traffico che giunge al router ha indirizzo destinazione 138.76.29.7.
In pratica, il router NAT nasconde i dettagli della rete domestica al mondo esterno. L'indirizzo dell'interfaccia del router viene assegnato dal server DHCP del provider. Sul router è in esecuzione un server DHCP per assegnare gli indirizzi ai dispositivi interni della rete. Ma se tutti i datagrammi che, dalla rete geografica, arrivano al router NAT hanno lo stesso indirizzo IP destinazione (quello dell'interfaccia del router NAT lato WAN), come fa il router a sapere a quale host interno deve inviare un datagramma?
Il router NAT usa una tabella di traduzione e, oltre agli indirizzi IP, inserisce i numeri di porta in ogni riga della tabella di traduzione. Ad esempio, un utente che usa l'host 10.0.0.1 richiede una pagina web ad un server web, che si trova all'indirizzo 128.119.40.186 ed è in ascolto sulla porta 80. L'host 10.0.0.1 assegna (arbitrariamente) il numero di porta sorgente 3345 al browser ed invia il datagramma sulla LAN. Il router NAT riceve il datagramma, genera un nuovo numero di porta sorgente 5001 per il datagramma, sostituisce l'indirizzo IP sorgente con il suo indirizzo IP lato WAN 138.76.29.7 e sostituisce il numero di porta 3345 con il nuovo numero 5001. Notare che al numero di porta sorgente sono riservati 16 bit, quindi si possono stabilire 65536 connessioni con un singolo indirizzo IP lato WAN. Il NAT nel router aggiunge una riga nella sua tabella di traduzione. Il server Web che riceve la richiesta ignora che il datagramma ricevuto è stato manipolato dal NAT, risponde con un datagramma il cui indirizzo IP di destinazione è l'indirizzo IP del router NAT e il numero di porta destinazione è 5001. Quando questo datagramma arriva al router NAT, il router accede alla tabella di traduzione per cercare una riga contenente quell'indirizzo IP e quel numero di porta destinazione ed estrae le informazioni associate, cioè l'indirizzo IP 10.0.0.1 e il numero di porta 3345 del browser. Il router riscrive l'indirizzo destinazione e il numero di porta destinazione così determinati e invia il pacchetto sulla rete interna.
Il NAT è stato ampiamente usato, ma ci sono alcune obiezioni. Primo, i numeri di porta identificano i processi non gli host. Questo potrebbe essere un problema se sulla rete interna c'è una applicazione in ascolto su una porta il cui numero è stato scelto dal router. Secondo, i router elaborano i pacchetti fino al livello 3. Terzo, gli host dovrebbero ritenere di dialogare direttamente, senza che dispositivi intermedi modifichino gli indirizzi IP e i numeri di porta. Si dovrebbe ricorrere al protocollo IPv6 per risolvere la carenza di indirizzi IP.
Un altro problema sollevato dal NAT è che interferisce con le applicazioni peer-to-peer, quali ad esempio la condivisione del file e la telefonia su IP. Il problema con queste applicazioni è che se un peer si trova oltre un router NAT, non può assumere il ruolo di server e accettare connessioni TCP.
Internet Control Message Protocol (ICMP)
A livello Rete di Internet ci sono tre protocolli: il protocollo IP, un protocollo di routing (RIP, OSPF e BGP) e il protocollo di servizio ICMP. ICMP è usato dagli host e dai router per scambiarsi informazioni di servizio. L'utilizzo tipico dell'ICMP riguarda la segnalazione degli errori. Ad esempio, durante una sessione Telnet, FTP, o HTTP, si possono verificare degli errori. Il messaggio di errore viene recapitato con un pacchetto ICMP. Ad esempio il messaggio "indirizzo destinazione non raggiungibile" è generato da un router che non riesce a trovare il percorso verso l'host destinatario del pacchetto Telnet, FTP o HTTP. Il router crea ed invia il messaggio del protocollo ICMP con l'indicazione dell'errore.
ICMP viene considerato un processo del livello Rete, ma in effetti risiede sopra il livello 3, in quanto il messaggio è incapsulato in un datagramma IP, così come lo sono i segmenti TCP e UDP. Analogamente, quando un host riceve un datagramma IP, in cui il campo "protocollo del livello superiore" specifica che il protocollo è ICMP, il datagramma viene consegnato al processo ICMP, così come viene fatto per i segmenti TCP o UDP.
I messaggi ICMP contengono nell'header un campo tipo, un campo codice e nel campo dati contengono i primi 8 byte del datagramma IP che ha causato la generazione del messaggio ICMP (in questo modo il mittente può determinare il datagramma che ha causato l'errore). la figura seguente riepiloga alcuni messaggi ICMP. Notare che essi non servono solo per segnalare errori.
| Tipo ICMP | Codice | Descrizione |
| 0 | 0 | echo reply (to ping) |
| 3 | 0 | destination network unreachable |
| 3 | 1 | destination host unreachable |
| 3 | 2 | destination protocol unreachable |
| 3 | 3 | destination port unreachable |
| 3 | 6 | destination network unknown |
| 3 | 7 | destination host unknown |
| 4 | 0 | source quench (congestion control) |
| 8 | 0 | echo request |
| 9 | 0 | router advertisement |
| 10 | 0 | router discovery |
| 11 | 0 | TTL expired |
| 12 | 0 | IP header bad |
Il comando ping invia un pacchetto ICMP con tipo=8 e codice=0 all'host destinazione specificato. L'host destinazione che riceve questo pacchetto "richiesta di eco" risponde con un pacchetto ICMP contenente il tipo=0 e il codice=0 (ICMP echo reply).
Un altro interessante messaggio ICMP è "source quench message". Lo scopo di questo messaggio era quello di consentire ad un router congestionato di chiedere all'host sorgente di rallentare la sua velocità di trasmissione. In effetti questo messaggio non è usato, il meccanismo di controllo della congestione è affidato al livello Trasporto.
Il programma Traceroute permette di ottenere l'elenco dei router attraversati da un pacchetto per raggiungere una certa destinazione. Per determinare i nomi e gli indirizzi dei router che si trovano tra una sorgente e una destinazione, Traceroute nell'host sorgente invia una serie di datagrammi IP alla destinazione. In ogni datagramma c'è un segmento UDP che specifica un numero di porta inesistente sul destinatario. Il primo datagramma ha TTL=1, il secondo ha TTL=2, il terzo ha TTL=3 e così via. Per ognuno dei datagrammi, la sorgente avvia un timer. quando l'n-mo datagramma arriva nell'n-mo router questo router osserva che il TTL è scaduto. Secondo la regola imposta dal protocollo IP, il router scarta questo pacchetto. però invia un messaggio di segnalazione al mittente (tipo=11, codice=0). Questo messaggio contiene il nome del router e il suo indirizzo IP. Quando il mittente riceve questo messaggio legge il tempo indicato dal timer, per conoscere il tempo trascorso dall'invio del pacchetto alla ricezione della risposta e legge il contenuto del pacchetto ICMP per conoscere l'indirizzo e il nome del router. Ma come fa TraceRoute a sapere quando fermare l'invio dei segmenti UDP? Si ricordi che il mittente incrementa il campo TTL per ogni pacchetto inviato. Quindi uno dei datagrammi attraverserà tutti i router che lo separano dalla destinazione. Poiché il datagramma che giunge a destinazione, contiene un segmento UDP che specifica un numero di porta inesistente, l'host destinazione invia al mittente un messaggio ICMP (tipo=3 codice=3) che ha il significato di "porta non raggiungibile". Quando il mittente riceve questo messaggio, sa che non ha bisogno di inviare altri messaggi. In questo modo l'host sorgente apprende le identità dei router che si trovano sul percorso verso la destinazione e il round-trip time tra i due host.
Il programma Traceroute deve essere in grado di chiedere al sistema operativo di generare segmenti UDP con specifici valori di TTL e deve anche essere in grado di farsi avvertire quando giunge un messaggio ICMP.
IPv6
Intorno al 1990 si decise di definire il successore di IPv4. La ragione principale era la constatazione che si stava esaurendo lo spazio degli indirizzi IP, cioè 32 bit si erano rivelati insufficienti. Iniziò quindi lo sviluppo di IPv6, anche con lo scopo di sopperire alle carenze dimostrate da IPv4. I progettisti di IPv6 hanno dovuto anche considerare quando il nuovo protocollo diventerà definitivamente operativo e non sarà più ammesso utilizzare IPv4. Nel febbraio del 2011 è stato assegnato ad un provider l'ultimo blocco di indirizzi IP disponibili. I provider dispongono ancora di indirizzi da assegnare, ma presto questi saranno assegnati, e si giungerà ad una situazione in cui nessuno potrà più acquistare un indirizzo IP per collegarsi a Internet. Un altro problema riguardava il tempo richiesto per installare la nuova tecnologia di indirizzamento su scala mondiale.
Il formato del datagramma IPv6
| 32 bit | ||||
| versione | Classe del traffico |
Flow label |
||
| lunghezza Payload |
Next header |
Hop limit |
||
| indirizzo IP sorgente (128 bit) |
||||
| indirizzo IP destinazione (128 bit) |
||||
| … Dati … |
||||
La figura precedente mostra il formato del datagramma IPv6. In questo sono evidenti le più importanti modifiche apportate:
Capacità di indirizzamento ampliata. IPv6 estende la dimensione di un indirizzo IP da 32 a 128 bit. Questo assicura che si può assegnare un indirizzo IP a ciascun atomo dell'universo. Inoltre, accanto agli indirizzi unicast e multicast, IPv6 introduce un nuovo tipo di indirizzo detto anycast, che consente di consegnare un datagramma agli host appartenenti ad un gruppo. Questa caratteristica potrebbe essere usata, ad esempio, per inviare una richiesta di pagina web al più vicino di un certo numero di host che possiede un documento.
Un header di 40 byte. Molti campi del formato IPv4 sono stati eliminati o resi facoltativi. L'intestazione risultante di 40 byte consente una più rapida elaborazione del datagramma IP. Una nuova codifica delle opzioni consente una elaborazione più flessibile.
Marcare il flusso e assegnare una priorità. IPv6 introduce la definizione di flusso: "pacchetti contrassegnati con una certa marca che appartengono ad una particolare comunicazione, per la quale il mittente chiede una gestione speciale", come un servizio real-time. Ad esempio, una trasmissione audio o video potrebbe essere trattata come un flusso. Le applicazioni quali il trasferimento file, la posta elettronica, potrebbero non essere considerate flussi. È possibile considerare flusso il traffico ad elevata priorità di un utente che acquista un servizio migliore. L'header di un pacchetto IPv6 ha anche un campo di 8 bit per specificare un campo "classe di traffico". Questo campo può servire per dare priorità a certi datagrammi di un flusso o certi datagrammi di certe applicazioni rispetto ad altre applicazioni.
Come notato, un confronto tra il formato del pacchetto IPv4 e il pacchetto IPv6 evidenzia la maggiore semplicità del pacchetto IPv6. In IPv6 sono definiti i seguenti campi:
Versione. Questo campo di 4 bit identifica il numero della versione del protocollo IP. Non ci si deve sorprendere che il valore deve essere 6.
Classe di Traffico. Questo campo di 8 bit ha un significato simile a quello del campo "Tipo di servizio" del pacchetto IPv4.
Marca del flusso. Questo campo di 20 bit Serve ad identificare i datagrammi che appartengono ad un flusso..
Lunghezza del Payload. Un campo di 16 bit, interpretato come un intero senza segno, che specifica il numero di byte riservati al payload, che si trova dopo i 40 byte dell'header del pacchetto IPv6.
Next header. Identifica il protocollo a cui si deve consegnare il contenuto (campo dati) di questo datagramma, ad esempio al TCP o all'UDP. I codici usati in questo campo per specificare il protocollo sono uguali a quelli usati in IPv4.
Hop limit. Il valore contenuto in questo campo viene decrementato di uno da ogni router che riceve il datagramma. Se il valore hop limit giunge a zero, il datagramma viene scartato.
Indirizzi Sorgente e destinazione. I vari formati degli indirizzi IPv6 a 128 bit sono descritti nella RFC 4291.
Dati. È il campo che rappresenta la parte payload del datagramma IPv6. Quando il datagramma raggiunge la destinazione finale, il payload sarà estratto dal datagramma e consegnato al protocollo specificato nel campo next header.
Confrontando il formato del pacchetto IPv4 con il formato del pacchetto IPv6 si nota che alcuni campi non sono più usati:
Fragmentation/Reassembly. IPv6 non permette che i router intermedi operino la frammentazione e il riassemblaggio dei datagrammi; queste operazioni possono essere eseguite solo alla sorgente e alla destinazione. Se un router riceve un datagramma che è troppo grande per l'altro router connesso al canale di uscita, il router scarta il datagramma e invia un messaggio ICMP con il codice: "Pacchetto troppo grande" per informare il mittente che il pacchetto deve essere frammentato. Il mittente rispedisce i dati, ma questa volta formando datagrammi più piccoli. Le operazioni di frammentazione e riassemblaggio incidono sulle prestazioni della trasmissione, quindi affidare il compito ai sistemi terminali anzichè ai router rende più veloce lo smistamento dei pacchetti da parte dei router.
Header checksum. Poiché i protocolli del livello Trasporto (TCP e UDP) e del livello Collegamento (ad esempio Ethernet) dei dispositivi in Internet già calcolano il Checksum, si è ritenuto opportuno eliminare questo campo dal datagramma IPv6. Si ricordi comunque che, poiché nell'header del datagramma IPv4 c'è il campo TTL (analogo al campo hop limit), il Checksum di IPv4 doveva essere ricalcolato in ogni router. Questa era un'operazione che sprecava il tempo di elaborazione del router.
Opzioni. Il campo Opzioni non è più un campo standard dell'header, ma non è scomparso. Il campo Opzioni è uno dei possibili next header puntati dall'interno dell'header IPv6. Cioè come il campo next header codifica il protocollo, TCP o UDP, del segmento contenuto nel payload del datagramma, così anche il campo Opzioni codifica l'header contenuta nel payload.
Si ricordi che il protocollo ICMP viene usato dai nodi IP per riportare, ai sistemi terminali, informazioni di errore o informazioni sullo stato dei canali. Con IPv6 è stata definita una nuova versione di IPv6, riorganizzando i tipi e i codici ICMP. ICMPv6 Ha introdotto anche nuovi tipi e nuovi codici associati alle nuove funzionalità di IPv6. Ad esempio, "Pacchetto troppo grande", "Opzione sconosciuta", ecc. Il protocollo ICMPv6 contiene le funzionalità del protocollo Internet Group Management Protocol (IGMP) che è usato per controllare un host che si aggiunge o si separa da un gruppo multicast, che prima di IPv6 era un protocollo separato.
Transizione da IPv4 a IPv6
Quando avverrà la transizione dallo schema IPv4 al nuovo modello IPv6? La difficoltà è che i sistemi IPv6 possono essere retro compatibili, cioè possono inviare, ricevere e instradare pacchetti IPv4, ma i sistemi IPv4 già installati, non sono in grado di trattare i datagrammi IPv6. Ci sono alcune ipotesi di soluzione.
Si potrebbe fissare un giorno in cui tutte le macchine vengono aggiornate contemporaneamente a IPv6. Un evento del genere avvenne negli anni '80 quando si abbandonò il protocollo NCP in favore del TCP. Persino quando Internet era una rete piccola e si dovevano amministrare poche reti, non si riteneva realizzabile una soluzione del genere, Oggi bisognerebbe coinvolgere centinaia di milioni di macchine e milioni di amministratori e utenti.
Ci sono due proposte per integrare gradualmente IPv6 nelle apparecchiature IPv4, con l'obiettivo a lungo termine di trasformare tutti i nodi IPv4 in nodi IPv6.
Probabilmente, il modo più efficace per introdurre IPv6 consiste nel realizzare un doppio livello rete, in cui i nodi IPv6 hanno anche l'implementazione IPv4. Un tale nodo, ha l'abilità di inviare e ricevere sia i datagrammi IPv4, sia i datagrammi IPv6. Quando interagisce con un nodo IPv4, usa il livello Rete IPv4, mentre quando interagisce con un nodo IPv6 interagisce usando il protocollo IPv6. L'interfaccia di un nodo IPv4/IPv6 deve avere entrambi gli indirizzi IPv4 e IPv6. Inoltre, i nodi IPv4/IPv6 devono essere in grado di determinare se un altro nodo è IPv6 o solo IPv4. Questo problema si risolve con il DNS, che restituisce un indirizzo IPv6 se il nome del nodo interrogato è dotato di IPv6, altrimenti restituisce un indirizzo IPv4. Naturalmente, se il nodo che genera l'interrogazione DNS è solo IPv4, il DNS restituisce solo un indirizzo IPv4.
Nell'approccio a doppio livello, se il mittente o il destinatario è solo IPv4, si devono usare solo datagrammi IPv4. Di conseguenza, potrebbe succedere che due nodi IPv6 continuino ad usare datagrammi IPv4. Si supponga che un nodo A, su cui funziona IPv6, debba inviare un datagramma al nodo F, anch'esso in grado di interpretare IPv6. I nodi A e B possono scambiarsi datagrammi IPv6, ma, ad esempio, il nodo B deve convertire il datagramma in IPv4 prima di spedirlo a C. La parte "dati" del datagramma IPv6 può essere ricopiata nella sezione "dati" del datagramma IPv4 e si può anche determinare l'indirizzo nel formato IPv4. Ci saranno alcuni campi IPv6 che non hanno il corrispondente in IPv6 (ad esempio il campo Identificatore di Flusso). Questa informazione sarà persa, così quando il datagramma IPv4 arriva nel nodo D non contiene tutti i campi del datagramma originale. Persino se il nodo E riconosce il formato IPv6, il datagramma resta nel formato IPv4, perché non si può risalire al datagramma originale generato da A.
Un'altra proposta è nota come tunneling. Il problema evidenziato nell'esempio viene risolto dal tunneling, ad esempio, il nodo E riceve il datagramma IPv6 generato da A. L'idea del tunneling è la seguente. Due nodi IPv6 vogliono scambiarsi datagrammi IPv6, ma sono interconnessi tramite sistemi intermedi IPv4. Questi router IPv4 intermedi formano il "tunnel". Quando un nodo IPv6, ad esempio B, deve inviare un datagramma nel tunnel, prende l'intero datagramma IPv6 e lo inserisce nel campo payload del pacchetto IPv4. Questo datagramma viene indirizzato al nodo IPv6 che si trova all'uscita del tunnel (ad esempio E) e consegnato al primo nodo del tunnel (ad esempio) C. I router IPv4 intermedi, che costituiscono il tunnel, fanno passare questo datagramma IPv4, ignorando che contiene un datagramma IPv6. Il nodo IPv6 sul lato ricevente del tunnel riceve il datagramma IPv4 (è indicato come nodo destinazione nel datagramma), Determina che il campo payload contiene un datagramma IPv6 e lo estrae, quindi lo instrada nel modo che avrebbe seguito se il datagramma gli fosse pervenuto da un nodo IPv6 direttamente connesso.
La proliferazione di dispositivi come i telefoni cellulari collegabili ad Internet offre una ulteriore spinta ad accelerare la diffusione di IPv6.
IPv6 ha evidenziato che è molto difficile cambiare il protocollo del livello Rete. Sarebbe come se si volessero sostituire le fondamenta di una casa. È difficile farlo senza far crollare l'edificio, o almeno si dovrebbe spostare temporaneamente la casa. In Internet è molto più facile aggiungere nuove applicazioni di rete, quindi nuovi protocolli del livello applicazione, è l'equivalente di aggiungere un nuovo piano ad una casa. Per il futuro ci si dovrebbe aspettare modifiche del livello Rete, molto rare rispetto alle modifiche del livello Applicazione.
Sicurezza del livello Rete
Il livello Rete non offre alcun servizio di sicurezza. Il protocollo IPv4 fu progettato in un'epoca (1970) in cui la rete era usata solo da ricercatori, e questi si fidavano dei dati scambiati. Cioè erano sicuri che i dati non erano stati modificati rispetto alla versione originale e che l'autore era realmente colui che asseriva di esserlo. L'impegno per progettare i protocolli del livello Rete era già sufficientemente complesso che non ci si preoccupò della sicurezza.
Nelle reti moderne la sicurezza è diventata un requisito fondamentale dei servizi offerti da Internet. Uno dei protocolli del livello Rete che introduce un meccanismo di sicurezza è IPsec, ampiamente usato nelle Virtual Private Network (VPN). IPsec è compatibile con IPv4 e IPv6. In particolare per usufruire dei vantaggi di IPsec non è necessario sostituire i protocolli negli host e nei router della rete Internet. Ad esempio IPsec possiede la modalità Trasporto, che permette a due host di comunicare in modo sicuro, anche se tutti i router e gli host continuano ad usare IPv4.
Nella modalità Trasporto, i due host stabiliscono prima una sessione (quindi IPsec, a livello Rete, offre un servizio connesso). Durante questa sessione tutti i segmenti TCP e UDP inviati tra i due host usufruiscono dei servizi di sicurezza offerti da IPsec. Dal lato mittente il livello Trasporto passa i segmenti a IPsec. IPsec cripta i segmenti, correda il pacchetto di altri campi necessari per il servizio sicuro, e incapsula tutto in un ordinario datagramma IP. Il mittente invia il datagramma in Internet, dove viaggia fino a raggiungere la destinazione. Qui, IPsec del ricevitore decripta il segmento e consegna il segmento decriptato al livello Trasporto.
IPsec fornisce i seguenti servizi:
Scelta della criptografia. In questa fase i due host che devono avviare la comunicazione si accordano su un algoritmo di criptografia e sulle chiavi di criptografia.
Criptografia dei dati. Quando il mittente riceve un segmento dal livello Trasporto IPsec cripta la parte payload del segmento. Questo poi, potrà essere decriptato solo da IPsec del destinatario.
Integrità dei dati. IPsec assicura che il datagramma ricevuto dal destinatario non ha subito modfiche lungo il percorso dalla sorgente al destinatario.
Autenticazione del mittente. Un host che riceve un datagramma da una sorgente fidata è sicuro che l'indirizzo IP sorgente indichi il vero indirizzo del mittente.
Quando due host hanno stabilito una sessione IPsec, tutti i segmenti TCP e UDP scambiati tra loro saranno criptati e autenticati. IPsec prevede pertanto copertura completa, fornendo la sicurezza alle applicazioni di rete in comunicazione tra due host. Una organizzazione può comunicare con sicurezza sulla rete pubblica Internet non sicura. Si pensi ad esempio ad una organizzazione che ha molti funzionari commerciali presso clienti distanti, ogni agente commerciale è dotato di un computer portatile. Questi ha bisogno di consultare informazioni riservate. L'installazione di IPsec sul server aziendale e sul computer dell'agente commerciale, che si collega, tramite la rete pubblica, al server garantisce che le informazioni trasferite, anche se venissero intercettate, non sono comprensibili a nessuno, e nessuno può modificarle durante il tragitto.
Aggregazione di indirizzi
Questo esempio di un provider che assegna blocchi di indirizzi a otto organizzazioni illustra il motivo per cui il CIDR agevola il routing.
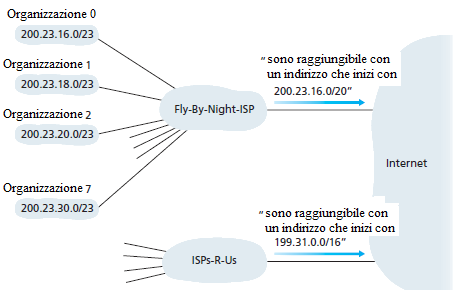
L'ISP (chiamato Fly-By-Night-ISP) rende noto, a tutti i computer del mondo, che ogni datagramma indirizzato ad un computer interno alla sua rete, deve avere i primi 20 bit dell'indirizzo impostati a 200.23.16.0/20. I computer del mondo non hanno bisogno di sapere che, all'interno del blocco di indirizzi 200.23.16.0/20, ci sono otto organizzazioni, ciascuna con una propria subnet. L'abilità di usare un solo prefisso per raggiungere più reti è detta "aggregazione di indirizzi".
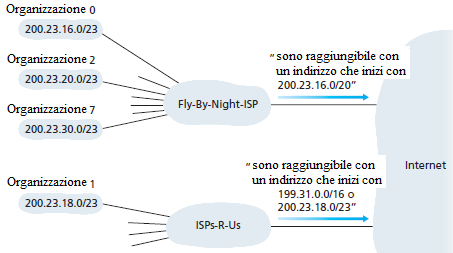
L'aggregazione degli indirizzi è una forma efficiente di assegnazione di blocchi di indirizzi agli ISP e, da questi, agli utenti finali. Ma cosa succede quando gli indirizzi non vengono assegnati gerarchicamente? Cosa succede, ad esempio, se Fly-By-Night-ISP assorbe un altro provider, ISPs-R-Us, e poi ha una Organizzazione 1 che preferisce connettersi a Internet attraverso il suo ISPs-R-Us? La figura mostra che ISPs-R-Us possiede il blocco di indirizzi 199.31.0.0/16, ma gli indirizzi IP dell'Organizzazione 1 sono esterni a questo intervallo. Come si può risolvere questo problema? L'Organizzazione 1 potrebbe rinumerare tutti i suoi host e i suoi router, in modo da assegnare a tutti solo indirizzi interni al blocco dell'ISPs-R-Us. Questa soluzione è costosa e, inoltre, in futuro l'Organizzazione 1 potrebbe scegliere ancora un altro provider.
La soluzione adottata è che l'Organizzazione 1 conservi i suoi indirizzi IP nell'intervallo 200.23.18.0/23. In questo caso, come mostra la figura, Fly-By-Night-ISP continua ad essere raggiungibile attraverso il blocco di indirizzi 200.23.16.0/20 e l'ISPs-R-Us attraverso il blocco 199.31.0.0/16. Comunque, adesso l'ISPs-R-Us deve essere raggiungibile anche attraverso il blocco di indirizzi dell'Organizzazione 1, 200.23.18.0/23. Quando altri router nella rete Internet vedono i blocchi di indirizzi 200.23.16.0/20 (da Fly-By-Night-ISP) e 200.23.18.0/23 (da ISPs-R-Us) e devono instradare pacchetti verso un indirizzo nel blocco 200.23.18.0/23, useranno il prefisso con la più lunga corrispondenza di bit uguali ai primi bit dell'indirizzo destinazione del pacchetto, ed instraderanno i pacchetti verso ISPs-R-Us.
Ispezionare datagrammi: Firewall e sistemi di riconoscimento delle intrusioni
Si supponga di essere l'amministratore di una rete (domestica, di una organizzazione, o altro). Gli attaccanti conoscono il range di indirizzi IP della rete, quindi possono facilmente inviare datagrammi IP agli indirizzi contenuti nel range. Questi datagrammi possono consentire agli attaccanti di scoprire la mappa della rete, le porte su cui le applicazioni sono in ascolto, produrre errori negli host, inviando pacchetti che non rispettano il protocollo, bombardare i server con pacchetti ICMP, ed infettare gli host con malware contenuti nei pacchetti.
All'amministratore di rete viene chiesto di prevenire questi attacchi. I meccanismi di difesa più diffusi sono i firewall ed i sistemi anti intrusione (IDSs). L'amministratore prova prima ad installare un firewall tra la rete e Internet (in particolare prima del router di accesso alla rete). I Firewall ispezionano i campi header del datagramma e, di conseguenza, negano l'accesso nella rete ai datagrammi che non soddisfano determinati criteri.
Ad esempio, un firewall può essere configurato per bloccare tutti i datagrammi ICMP, impedendo, quindi, ad un attaccante di inondare la rete con pacchetti Ping. I firewall possono anche discriminare i pacchetti osservando l'indirizzo IP destinazione o sorgente, o anche i numeri di porta. Inoltre i firewall possono anche osservare le connessioni TCP in corso e consentire il passaggio solo dei pacchetti appartenenti a tali connessioni.
Una ulteriore protezione può essere fornita dagli IDS. Questi, in genere, si trovano sul router di frontiera della rete. Questi esaminano accuratamente i pacchetti entranti, non solo l'header, ma anche il payload, compreso i dati del livello applicazione. Un IDS possiede un database con le caratteristiche dei pacchetti che vengono usati per attaccare una rete. Queste caratteristiche sono dette "Firme". Ogni volta che si scopre una nuova tecnica di attacco, il database viene aggiornato.
Quando l'IDS acquisisce un pacchetto confronta i campi dell'header e del payload per individuare la presenza di una Firma nel database. Se questa viene individuata, si genera un allarme. Un sistema di prevenzione delle intrusioni funziona in maniera analoga, la differenza è che blocca anche i pacchetti, oltre a generare l'allarme.
I firewall e i sistemi anti intrusione proteggono la rete contro gli attacchi noti, ma non possono schermare completamente la rete da tutti i possibili attacchi. Gli attaccanti sono alla costante ricerca di nuove tecniche che abbiano firme sconosciute.