Bibliografia:
Computer Networking. Cap. 3. Autori: James F. Kurose (University of Massachusetts, Amherst) Keith W. Ross (Polytechnic Institute of NYU).
Il protocollo http.
Fino al 1990 la rete Internet era utilizzata principalmente da ricercatori, accademici e studenti universitari per accedere a host remoti, per trasferire file da host locali a host remoti e viceversa, per ricevere e inviare notizie e per ricevere e inviare posta elettronica. Sebbene queste applicazioni erano (e continuano ad essere) estremamente utili, Internet era sostanzialmente sconosciuta al di fuori delle comunità accademiche e di ricerca. Poi, dal 1990, una nuova importante applicazione è arrivata sulla scena, il World Wide Web. Il Web è stata la prima applicazione Internet che ha catturato l'interesse del pubblico in generale. Il modo in cui le persone interagiscono dentro e fuori dei loro ambienti di lavoro è cambiato e continua a cambiare radicalmente. Internet è passata da una delle tante reti dati a la sola e unica rete dati.
Il Web funziona su richiesta. Gli utenti ricevono quello che vogliono, quando lo vogliono. Questo è diverso dalle trasmissioni radio e televisive tradizionali, che costringono gli utenti ad aspettare quando il fornitore rende disponibili i contenuti. Oltre ad essere disponibile a richiesta, il Web ha molte altre caratteristiche molto apprezzate. Ogni persona può pubblicare articoli sul web a costi estremamente bassi. I collegamenti ipertestuali e i motori di ricerca aiutano a navigare attraverso i siti web. La grafica produce effetti molto efficaci. Ci sono molte tecniche per interagire con le pagine web. Sul web si appoggiano le più diffuse applicazioni nate dopo il 2003, tra cui YouTube, Gmail e Facebook
Panoramica di HTTP
L'HyperText Transfer Protocol (HTTP) è il protocollo del Web. È definito nelle RFC 1945 e RFC 2616. HTTP è implementato in due programmi: uno client e uno server. Il programma client e il programma server, in esecuzione su sistemi terminali diversi, dialogano tra loro scambiandosi messaggi. HTTP definisce la struttura di questi messaggi e il modo in cui il client e il server si scambiano i messaggi.
Una pagina Web (chiamata anche un documento) consiste di oggetti. Un oggetto è semplicemente un file, ad esempio un file HTML, un'immagine JPEG, un'applet Java, o un video clip, indirizzabili con un singolo URL. La maggior parte delle pagine Web sono costituite da un file HTML di base e diversi oggetti riferiti. Ad esempio, se una pagina Web contiene un testo HTML e cinque immagini JPEG, la pagina Web ha sei oggetti: il file HTML di base più le cinque immagini. Il file HTML di base contiene i riferimenti (URL) agli altri oggetti da mostrare nella pagina. Ogni URL ha due componenti: il nome host del server che ospita l'oggetto e il percorso dell'oggetto. Ad esempio, l'URL:
http://www.scuola.edu/dipartimento/figura.gif
ha www.scuola.edu come hostname e /dipartimento/figura.gif come nome di percorso. Poichè il lato client di HTTP è implementano dai browser Web (come Internet Explorer e Firefox), nel contesto del Web i due termini browser e client sono usati come sinonimi. I Server Web, che implementano il lato server dell'HTTP, ospitano oggetti, ciascuno indirizzabile con un URL.
I Server Web più diffusi sono Apache e Microsoft Internet Information Server. HTTP definisce come i client Web richiedono le pagine Web ai server Web e come i server Web trasferiscono le pagine Web ai client. Quando un utente richiede una pagina Web (ad esempio, fa clic su un collegamento ipertestuale), il browser invia al server i messaggi di richiesta HTTP per gli oggetti contenuti nella pagina. Il server riceve le richieste e replica con messaggi di risposta HTTP che contengono gli oggetti. Il protocollo HTTP utilizza TCP come protocollo di trasporto sottostante. Il client HTTP deve chiedere di aprire una connessione TCP con il server.
Una volta stabilita la connessione, i processi del browser e del server hanno accesso al TCP attraverso le loro interfacce socket. Sul lato client dell'interfaccia socket c'è la porta tra il processo client e la connessione TCP; sul lato server c'è la porta tra il processo server e la connessione TCP. Attraverso l'interfaccia del socket, il client invia messaggi di richiesta HTTP e riceve i messaggi di risposta HTTP. Allo stesso modo, attraverso la sua interfaccia socket, il server riceve i messaggi di richiesta HTTP ed invia i messaggi di risposta HTTP. Una volta che il client invia un messaggio sulla sua interfaccia socket, il messaggio è sotto il controllo del TCP.
Il TCP fornisce all'http un servizio di trasferimento affidabile dei dati. Ciò significa che ciascun messaggio di richiesta HTTP inviato da un processo client arriva intatto al server; Analogamente, ciascun messaggio di risposta HTTP inviato dal processo server arriva intatto al client. Qui si vede uno dei grandi vantaggi dell'architettura stratificata: HTTP non si deve preoccupare della perdita dei dati o di come TCP recupera i dati persi nè come questi verranno riordinati. Questo è il compito del TCP e dei protocolli dei livelli sottostanti.
È importante notare che il server invia un file al client che lo ha richiesto senza memorizzare le informazioni relative al client. Se un particolare client richiede lo stesso oggetto due volte a distanza di pochi secondi, il server non risponde dicendo che ha appena inviato l'oggetto al client, il server invia nuovamente l'oggetto, come se si fosse completamente dimenticato di quello che ha fatto in precedenza. Poichè un server HTTP non mantiene le informazioni sui client, HTTP si dice che è un protocollo stateless. Il Web utilizza l'architettura client-server per le applicazioni. Un server Web è sempre acceso, ha un indirizzo IP fisso, e soddisfa richieste provenienti da numerosi browser.
Connessioni Non-Persistenti e Persistenti
In molte applicazioni Internet, il client e il server comunicano per un periodo di tempo prolungato, con il client che effettua una serie di richieste e il server che risponde a ciascuna di esse. A seconda dell'applicazione e di come viene utilizzata, la serie di richieste può avvenire consecutivamente, periodicamente, ad intervalli regolari, o a intermittenza. Quando questa interazione client-server si svolge su TCP, lo sviluppatore dell'applicazione deve prendere una decisione importante: ogni coppia "richiesta/risposta" dovrebbe viaggiare su una nuova connessione TCP, oppure tutte le richieste e le loro risposte corrispondenti devono viaggiare sulla stessa connessione TCP? Nel primo approccio, si decise che l'applicazione avrebbe utilizzato le connessioni non persistenti; successivamente si ritenne conveniente usare le connessioni persistenti. Per comprendere questo problema di progettazione, conviene esaminare i vantaggi e gli svantaggi delle connessioni persistenti nel contesto di una specifica applicazione, vale a dire HTTP, che può utilizzare sia le connessioni non persistenti sia le connessioni persistenti. Sebbene HTTP utilizzi connessioni persistenti in modalità predefinita, i client e i server HTTP possono essere configurati per utilizzare le connessioni non persistenti.
HTTP con Connessioni Non-Persistenti
Si seguano le fasi di trasferimento di una pagina Web dal server al client nel caso di connessioni non persistenti. Si supponga che la pagina sia costituita da un file HTML di base e 10 immagini in formato JPEG, e che tutti gli 11 oggetti risiedano sullo stesso server. Se l'URL del file HTML di base è:
http://www.scuola.edu/dipartimento/home.htm
Ecco cosa succede:
Il processo client HTTP chiede l'apertura di una connessione TCP con il server www.scuola.edu in ascolto sulla porta numero 80, che è il numero di porta predefinito per HTTP. Associato alla connessione TCP, ci sarà un socket sul client e un socket sul server.
Il client HTTP invia un messaggio di richiesta HTTP al server tramite il suo socket. Il messaggio di richiesta contiene il percorso /scuola/home.htm.
Il processo server HTTP riceve il messaggio di richiesta attraverso il suo socket, recupera l'oggetto /scuola/home.htm dal suo disco, incapsula l'oggetto in un messaggio di risposta HTTP, ed invia il messaggio di risposta al client tramite il suo socket.
Il processo server HTTP dice al TCP di chiudere la connessione. (TCP in realtà non termina la connessione fino a quando non sa per certo che il client ha ricevuto intatto il messaggio di risposta).
Il client HTTP riceve il messaggio di risposta. La connessione TCP viene rilasciata. Il messaggio indica che l'oggetto incapsulato è un file HTML. Il client estrae il file dal messaggio di risposta, esamina il file HTML, e trova i riferimenti ai 10 oggetti JPEG.
I primi quattro passaggi vengono ripetuti per ciascuno dei 10 oggetti JPEG riferiti.
Due browser diversi possono interpretare (cioè mostrare all'utente) la stessa pagina Web in modi differenti. HTTP non ha nulla a che fare con il modo in cui una pagina Web viene interpretata da un client. Le specifiche HTTP definiscono solo il protocollo di comunicazione tra il programma client HTTP e il programma server HTTP.
I passaggi descritti prima illustrano l'uso delle connessioni non persistenti, dove ogni connessione TCP viene chiusa dopo che il server invia l'oggetto, cioè la connessione non persiste per altri oggetti. Si noti che ogni connessione TCP trasporta esattamente un messaggio di richiesta e un messaggio di risposta. Quindi, in questo esempio, quando un utente richiede la pagina Web, si generano 11 connessioni TCP.
Nelle fasi sopra descritte, non si è precisato se il client ottiene le 10 immagini JPEG con 10 connessioni TCP seriali, o se alcuni dei file JPEG sono ottenuti tramite le connessioni TCP in parallelo. Infatti, gli utenti possono configurare i browser moderni per controllare il grado di parallelismo. Per default, i browser aprono da 5 a 10 connessioni TCP in parallelo, e ciascuna di queste connessioni gestisce una transazione richiesta-risposta. Se l'utente preferisce, il numero massimo di connessioni parallele può essere impostato a uno, nel qual caso le 10 connessioni sono stabilite in modo seriale. L'utilizzo di connessioni in parallelo accorcia i tempi di risposta.
Prima di continuare, si faccia un calcolo per stimare la quantità di tempo che intercorre da quando un client richiede il file HTML di base fino a quando l'intero file viene ricevuto dal client. A tal fine, si definisce il tempo di andata e ritorno (Round Trip Time, RTT), che è il tempo che impiega un pacchetto per viaggiare dal client al server e poi di nuovo al client. L'RTT è la somma dei ritardi di propagazione del pacchetto lungo il canale, più i ritardi per lo smistamento del pacchetto nei router intermedi, più i ritardi di elaborazione del pacchetto. Si consideri ora cosa accade quando un utente fa clic su un collegamento ipertestuale.
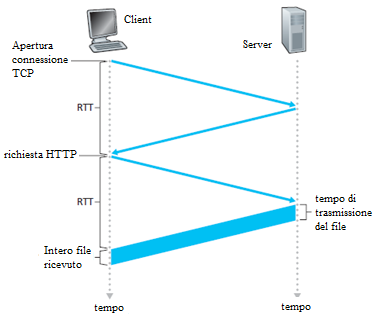
Il browser invia la richiesta di "apertura connessione TCP" al server Web; questo comporta un "handshake a tre vie": il client invia un piccolo segmento TCP al server, il server riconosce e risponde con un segmento TCP, ed infine, il client invia la conferma al server. Le prime due parti dell'handshake a tre vie consumano un RTT. Dopo aver completato le prime due parti dell'handshake, il client invia il messaggio di richiesta HTTP combinato con la terza parte del three-way handshake (il riconoscimento) sulla connessione TCP. Una volta che il messaggio di richiesta arriva al server, il server invia il file HTML sulla connessione TCP. Questa richiesta e risposta HTTP consuma un altro RTT. Così, grosso modo, il tempo di risposta totale è di due RTT più il tempo di trasmissione dell'intero file HTML.
HTTP con Connessioni Persistenti
Le connessioni non persistenti hanno alcune lacune. In primo luogo, si deve stabilire un nuovo collegamento e mantenerlo per ogni oggetto richiesto. Per ciascuna di queste connessioni, si devono riservare i buffer TCP e le variabili TCP sia sul client sia sul server. Questo consuma risorse sul server Web, che può ricevere richieste da numerosi altri client contemporaneamente. In secondo luogo, ogni oggetto subisce un ritardo di consegna di due RTT: uno per stabilire la connessione TCP e uno per richiedere e ricevere un oggetto.
Con le connessioni persistenti, il server lascia la connessione TCP aperta dopo l'invio di una risposta. Le successive richieste e risposte tra lo stesso client e server possono essere inviate sulla stessa connessione. In particolare, un'intera pagina Web (nell'esempio precedente, il file HTML di base e le 10 immagini) possono essere inviate attraverso una singola connessione TCP persistente.
Inoltre, più pagine Web che risiedono sullo stesso server possono essere inviate dal server allo stesso client su una singola connessione TCP persistente. Le richieste per gli oggetti possono essere effettuate in successione, senza aspettare risposte alle richieste in sospeso (pipelining). Tipicamente, il server HTTP chiude la connessione quando non viene utilizzato per un certo tempo (un intervallo di timeout configurabile). Quando il server riceve le richieste una dopo l'altra, invia gli oggetti uno dopo l'altro. La modalità predefinita di HTTP utilizza connessioni persistenti con pipelining.
Formato dei messaggi HTTP
Le specifiche HTTP comprendono le definizioni dei formati dei messaggi HTTP. Ci sono due tipi di messaggi HTTP, i messaggi di richiesta e i messaggi di risposta, entrambi sono discussi di seguito.
Messaggio HTTP request
Un tipico messaggio HTTP request:
GET /unadir/pagina.html HTTP/1.1 Host: www.scuola.edu Connection: close User-agent: Mozilla/5.0 Accept-language: fr
Prima di tutto, si vede che il messaggio è un testo in codice ASCII. Inoltre, il messaggio si compone di cinque linee, ognuna seguita da un ritorno a capo (CR: Carriage Return) e un avanzamento riga (LF: Line Feed). L'ultima riga è seguita da un ritorno a capo e un avanzamento riga supplementare. Questo particolare messaggio di richiesta ha cinque linee, ma un messaggio di richiesta può averne molte di più o anche solo una. La prima riga di un messaggio di richiesta HTTP è chiamata linea di richiesta; le righe successive sono chiamate le righe di intestazione. La linea di richiesta è suddivisa in tre campi: il campo del metodo, il campo URL, e il campo versione HTTP. Il campo metodo può assumere diversi valori, tra cui GET, POST, HEAD, PUT e DELETE.
Il metodo GET viene utilizzato quando il browser richiede un oggetto, che è specificato nel campo URL. In questo esempio, il browser richiede l'oggetto /unadir/pagina.html. e il terzo campo specifica che il browser implementa la versione HTTP/1.1.
Dopo la riga di richiesta, nell'esempio, ci sono le righe di intestazione. La riga di intestazione Host: www.scuola.edu specifica l'host su cui risiede l'oggetto. Si potrebbe pensare che questa riga di intestazione non sia necessaria, in quanto vi è già una connessione TCP in atto verso l'host, ma le informazioni fornite dalla linea di intestazione host sono sfruttate dalla cache Web. Includendo la riga di intestazione Connection: close, il browser sta dicendo al server che non vuole usare connessioni persistenti; vuole che il server chiuda la connessione dopo l'invio dell'oggetto richiesto. La riga di intestazione User-agent: specifica il tipo di browser che effettua la richiesta al server. Qui l'User Agent è Mozilla/5.0, il browser Firefox. Questa linea di intestazione è utile perchè il server potrebbe inviare differenti versioni dello stesso oggetto ai diversi tipi di browser. Infine, la riga di intestazione Accept-language: indica che l'utente preferisce ricevere una versione francese dell'oggetto, se un tale oggetto esiste sul server; in caso contrario, il server deve inviare la sua versione predefinita. L'intestazione Accept-language: è solo una delle intestazioni di negoziazione dei contenuti disponibili in HTTP.
| Linea Request ⇒ | Method | [spazio] | URL | [spazio] | Versione | CR | LF |
| linee Header ⇒ | Nome campo Header: | [spazio] | Valore | CR | LF | ||
| … | … | … | … | … | |||
| Nome campo Header: | [spazio] | Valore | CR | LF | |||
| Riga vuota ⇒ | CR | LF | |||||
| Body ⇒ | |||||||
Dopo l'esempio, si osservi il formato generale di un messaggio di richiesta. Dalla figura si vede che il formato generale rispetta l'esempio precedente. Dopo le righe di intestazione (e un'altra coppia di caratteri ritorno a capo e avanzamento riga), c'è un "corpo di entità". Il corpo è vuoto se si specifica il metodo GET, ma viene utilizzato se si specifica il metodo POST. Un client HTTP usa spesso il metodo POST quando l'utente compila un form, per esempio. Con un messaggio POST, l'utente sta ancora chiedendo una pagina Web al server, ma i contenuti specifici della pagina Web dipendono da ciò che l'utente ha immesso nei campi del form. Se il valore del campo metodo è POST, allora il corpo contiene ciò che l'utente ha immesso nei campi del form.
In HTML è ammesso inviare i dati al server anche con il metodo GET di seguito all'URL richiesto. Ad esempio, se un modulo utilizza il metodo GET ed ha due campi, i cui valori sono "scimmie" e "banane", l'URL avrà la forma: www.unsito.com/cercaanimale?quale=scimmie&mangia=banane.
Il metodo HEAD è simile al metodo GET. Quando un server riceve una richiesta con il metodo HEAD, risponde con un messaggio HTTP ma lascia vuoto il campo BODY, cioè non invia l'oggetto richiesto. Gli sviluppatori di applicazioni utilizzano il metodo HEAD per il debug.
Il metodo PUT è usato in combinazione con la pubblicazione sul web. Esso consente all'utente di caricare un oggetto in un percorso specifico (directory) su un server Web specifico. Il metodo PUT è utilizzato anche dalle applicazioni che necessitano di caricare oggetti sui server Web. Il metodo DELETE consente a un utente o ad un'applicazione, di eliminare un oggetto su un server web.
Messaggi HTTP Response
Il seguente è un esempio di pacchetto HTTP response. Potrebbe essere la risposta alla richiesta precedente:
HTTP/1.1 200 OK
Connection: close
Date: Tue, 09 Aug 2011 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(… dati …)
Questa risposta ha tre sezioni: una riga di stato, sei righe di intestazione, e poi il corpo del messaggio di risposta. Il corpo del messaggio è l'oggetto richiesto (rappresentato da (… dati …)). La riga di stato ha tre campi: il campo di versione del protocollo, un codice di stato e il corrispondente messaggio di stato. In questo esempio, la riga di stato indica che il server utilizza HTTP/1.1 e che tutto è OK (cioè, il server ha trovato, e sta inviando, l'oggetto richiesto).
Il server utilizza la riga di intestazione Connection: close per dire al client che chiuderà la connessione TCP dopo l'invio del messaggio di risposta. La linea di intestazione Data: indica l'ora e la data in cui la risposta HTTP è stata creata e inviata dal server. Si noti che questo non è il momento in cui l'oggetto è stato creato o modificato l'ultima volta, ma è il momento in cui il server recupera l'oggetto dal suo file system, inserisce l'oggetto nel messaggio di risposta, e invia il messaggio di risposta. La riga di intestazione Server: indica che il messaggio è stato generato da un server Web Apache; è analoga alla riga di intestazione User-Agent: nel messaggio di richiesta HTTP.
La riga di intestazione Last-Modified: indica l'ora e la data in cui l'oggetto è stato creato o modificato l'ultima volta. L'intestazione Last-Modified: è fondamentale per la memorizzazione nella cache, sia nel client locale sia nella cache di rete (nota anche come server proxy). La riga di intestazione Content-Length: indica il numero di byte nell'oggetto inviato. La riga di intestazione Content-Type: indica che l'oggetto nel BODY è un testo HTML. (Il tipo di oggetto è specificato dal Content-Type: e non dall'estensione del file).
| Riga di stato ⇒ | Versione | [spazio] | Codice di stato | [spazio] | Messaggio | CR | LF |
| linee Header ⇒ | Nome campo Header: | [spazio] | Valore | CR | LF | ||
| … | … | … | … | … | |||
| Nome campo Header: | [spazio] | Valore | CR | LF | |||
| Riga vuota ⇒ | CR | LF | |||||
| Body ⇒ | |||||||
Dopo aver visto un esempio, si esamini ora il formato generale di un messaggio di risposta, che è mostrato nella figura. Questo formato generale del messaggio di risposta corrisponde al precedente esempio. Il codice di stato e la descrizione associata indicano l'esito della richiesta. Alcuni codici di stato sono:
200 OK: Request succeeded e quindi nella risposta c'è l'informazione.
301 Moved Permanently: L'oggetto richiesto è stato spostato in modo permanente; il nuovo URL è specificato nell'header Location: del messaggio di risposta. Il client recupererà automaticamente il nuovo URL.
400 Bad Request: Questo è un codice di errore generico che indica che la richiesta non può essere compresa dal server.
404 Not Found: Il documento richiesto non esiste su questo server.
505 HTTP Version Not Supported: La versione del protocollo HTTP richiesta non è supportata dal server.
Per vedere un vero e proprio messaggio di risposta http, avviare Telnet e collegarsi ad un server Web preferito. Quindi digitare un messaggio di richiesta. Ad esempio, se si ha accesso a un prompt dei comandi digitare:
telnet cis.poly.edu 80
GET /~ross/ HTTP/1.1
Host: cis.poly.edu
(Premere due volte il tasto "Invio" dopo aver digitato l'ultima riga). Si apre una connessione TCP sulla porta 80 dell'host cis.poly.edu e poi si invia il messaggio di richiesta HTTP. Si dovrebbe vedere un messaggio di risposta che include il file HTML della homepage del professor Ross. Se si preferisce vedere solo le linee del messaggio HTTP e non ricevere l'oggetto, sostituire GET con HEAD. Infine, sostituire /~ross/ con /~banane/ e vedere che tipo di messaggio di risposta si ottiene.
In questa sezione sono state descritte alcune righe di intestazione che possono trovarsi all'interno di una richiesta o di una risposta HTTP. Le specifiche HTTP definiscono molte altre righe di intestazione che possono essere inserite dai browser, dai server Web o dai server di cache della rete. Sono state descritte poche linee di intestazione.
Come fa un browser a decidere quali linee di intestazione deve includere in un messaggio di richiesta? Come fa un server Web a decidere quali linee di intestazione deve includere in un messaggio di risposta? Un browser genererà linee di intestazione in funzione del tipo e della versione del browser (ad esempio, un browser HTTP/1.0 non genererà alcuna linea di intestazione), della configurazione del browser dell'utente (ad esempio, la lingua preferita) e, se il browser attualmente ha nella sua cache, la versione non aggiornata dell'oggetto. I Server Web si comportano in modo simile: Ci sono diversi prodotti, versioni e configurazioni, tutte influenzano le intestazioni incluse nei messaggi di risposta.
Interazione Utente-Server: I Cookie
Si ricordi che un server HTTP è stateless. Questo semplifica la progettazione dei server e permette ai tecnici di sviluppare server Web ad alte prestazioni in grado di gestire migliaia di connessioni TCP simultanee. Tuttavia, un sito Web potrebbe aver bisogno di identificare gli utenti, ad esempio perchè il server intende limitare l'accesso dell'utente oppure perchè vuole servire contenuti in funzione dell'identità dell'utente. Per questi scopi, HTTP utilizza i cookie. I cookie consentono ai siti di tenere traccia degli utenti. I principali siti Web commerciali utilizzano i cookie.
La tecnologia dei cookie ha quattro componenti: (1) una linea di intestazione cookie nel messaggio di risposta HTTP; (2) una riga di intestazione cookie nel messaggio di richiesta HTTP; (3) un file cookie mantenuto sul sistema terminale dell'utente e gestito dal browser dell'utente; e (4) un database back-end presso il sito web. Si osservi l'esempio della figura. Si supponga che Susanna, accedendo al Web sempre con lo stesso browser dal suo PC di casa, contatti Amazon.com per la prima volta. Si supponga che in passato abbia già visitato il sito eBay.
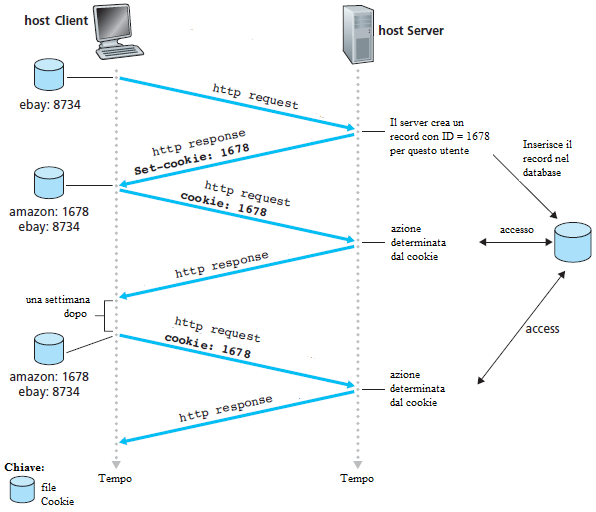
Quando la richiesta arriva al server Web di Amazon, il server crea un numero di identificazione univoco e crea una voce nel proprio database back-end che viene indicizzato dal numero di identificazione. Il server Web di Amazon risponde quindi al browser di Susanna, includendo nella risposta HTTP un header Set-Cookie:, che contiene il numero di identificazione. Ad esempio, la riga di intestazione potrebbe essere:
Set-cookie: 1678
Quando il browser di Susanna riceve il messaggio di risposta HTTP, vede l'intestazione Set-Cookie:. Il browser allora aggiunge una riga al file del cookie. Questa linea include il nome host del server e il numero di identificazione dell'header Set-Cookie:. Si noti che il file del cookie ha già una voce per eBay, dal momento che Susanna ha visitato quel sito in passato. Mentre Susanna continua a navigare sul sito di Amazon, ogni volta che richiede una pagina Web, il suo browser consulta il suo file del cookie, estrae il numero di identificazione di questo sito, e mette una riga di intestazione cookie che include il numero di identificazione nella richiesta HTTP. In particolare, ciascuna delle richieste HTTP al server di Amazon include la riga di intestazione:
Cookie: 1678
In questo modo, il server di Amazon è in grado di monitorare l'attività di Susanna sul sito di Amazon. Il sito di Amazon non conosce il nome di Susanna, ma sa esattamente quali pagine ha visitato l'utente numero 1678, in quale ordine, e in quale momento! Amazon utilizza i cookie per fornire il proprio carrello di servizio. Amazon può mantenere un elenco di tutti gli acquisti che Susanna intende effettuare, in modo che lei possa pagarli insieme, alla fine della sessione.
Se Susanna torna al sito di Amazon, per esempio, una settimana dopo, il suo browser continuerà a mettere la riga di intestazione Cookie: 1.678 nei messaggi di richiesta. Amazon suggerisce a Susanna anche i prodotti di suo possibile interesse, basandosi sulle pagine Web che ha visitato in passato su Amazon. Se Susanna si registra su Amazon, fornendo nome, cognome, indirizzo e-mail, indirizzo postale, carta di credito e altre informazioni, Amazon può includere queste informazioni nel suo database, associando così il nome di Susanna con il suo numero di identificazione (e di tutte le pagine che ha visitato presso il sito in passato!). Questo è il modo in cui Amazon e altri siti di e-commerce offrono "one-click shopping". Quando Susanna sceglie di acquistare un oggetto durante una visita successiva, lei non ha bisogno di reinserire il suo nome, il suo numero di carta di credito o il suo indirizzo.
Da quanto osservato, si vede che i cookie possono essere utilizzati per identificare un utente. La prima volta che un utente visita un sito, può fornire un identificativo utente (eventualmente il suo nome). Durante le sessioni successive, il browser passa un'intestazione cookie al server, in tal modo l'utente è individuato dal server. I cookie possono quindi essere usati per creare un livello di sessione utente appoggiato all'http, che non mantiene lo stato. Ad esempio, quando un utente accede ad un'applicazione di posta elettronica Web (come Hotmail), il browser invia al server le informazioni contenute nei cookie, permettendo al server di identificare l'utente durante la sessione.
Anche se i cookie semplificano lo shopping su Internet, possono essere considerati come una violazione della privacy. Come si è appena visto, utilizzando una combinazione di cookie e le informazioni sull'account utente, un sito Web può identificare un utente e potenzialmente potrebbe vendere queste informazioni a terzi.
Web Caching
Una Web cache - anche detta proxy server - è un'entità di rete che soddisfa le richieste HTTP per conto di un server Web. La cache Web risiede su disco e mantiene copie degli oggetti recentemente richiesti. Il browser di un utente può essere configurato in modo che tutte le richieste HTTP dell'utente vengano prima indirizzate alla cache Web. Come esempio, si supponga che un browser richieda l'oggetto http://www.scuola.edu/home.jpg. Succede:
Il browser apre una connessione TCP con la cache Web e, a questa, invia la richiesta HTTP per ottenere l'oggetto.
La cache Web controlla se ha una copia dell'oggetto memorizzato localmente. Se ce l'ha, la cache Web restituisce l'oggetto all'interno di un messaggio di risposta HTTP al browser del client.
Se la cache Web non ha l'oggetto, la cache Web apre una connessione TCP con il server di origine, cioè con www.scuola.edu e, su questa connessione TCP tra la cache ed il server, invia una richiesta HTTP per l'oggetto. Dopo aver ricevuto questa richiesta, il server di origine invia l'oggetto all'interno di una risposta HTTP alla cache Web.
Quando la cache Web riceve l'oggetto, se ne fa una copia locale ed invia l'oggetto all'interno di un messaggio di risposta HTTP, al browser (sulla connessione TCP esistente tra il browser client e la cache Web). Si noti che una cache è sia un server sia un client allo stesso tempo. Quando riceve richieste da un browser ed invia le risposte a un browser, è un server. Quando invia richieste e riceve risposte da un server web, è un client.
Il Caching Web è stato distribuito in Internet per due motivi. In primo luogo, una cache Web può ridurre sensibilmente il tempo di risposta per una richiesta da parte di un client, in particolare se la larghezza di banda tra il client e il server web è molto minore della larghezza di banda tra il client e la cache. Se c'è una connessione ad alta velocità tra il client e la cache, come spesso c'è, e se la cache ha l'oggetto richiesto, allora la cache sarà in grado di fornire rapidamente l'oggetto al client. In secondo luogo, come si vedrà, le cache Web possono ridurre sensibilmente il traffico sul collegamento di accesso a Internet. Riducendo il traffico, l'ente (per esempio, una società o una università) non deve aumentare la larghezza di banda, mantenendo così i costi bassi, inoltre, la riduzione del traffico in Internet, migliora le prestazioni per tutte le applicazioni.
Per comprendere i vantaggi della cache, si consideri un esempio. Si abbiano due reti - una rete istituzionale e la rete Internet. La rete istituzionale è una LAN ad alta velocità. Un router nella rete istituzionale e un router in Internet sono collegati da una linea a 15 Mbps. I server di origine sono collegati a Internet, e si possono trovare in qualsiasi parte del mondo. Si supponga che la dimensione media di un oggetto sia di 1 Mbit e che il tasso medio di richieste dal browser ai server di origine sia di 15 richieste al secondo. Si supponga che i messaggi di richiesta HTTP siano tanto piccoli da poter ritenere che non creino traffico nelle reti o nel canale di accesso. Inoltre si supponga che il tempo che intercorre da quando il router sul lato Internet del canale inoltra una richiesta HTTP (all'interno di un datagram IP) finchè non riceve la risposta (in genere all'interno di molti pacchetti IP) è di due secondi in media. Questo ultimo ritardo verrà riferito come il "ritardo Internet".
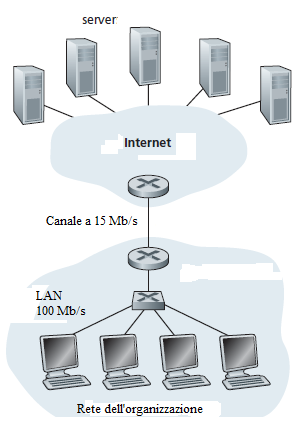
Il tempo totale di risposta, cioè il tempo che passa da quando il browser emette la richiesta di un oggetto fino a quando riceve l'oggetto, è la somma del ritardo della LAN, del ritardo di accesso (cioè, il ritardo tra i due router), e il ritardo Internet. Un calcolo grossolano per stimare questo ritardo, consiste nel calcolare l'intensità del traffico sulla LAN:
(15 richieste/sec)·(1 Mbit/richiesta)/(100 Mbps) = 0.15,
mentre l'intensità del traffico sul collegamento dal router Internet al router istituzionale è:
(15 richieste/sec)·(1 Mbit/richiesta)/(15 Mbps) = 1
Una intensità di traffico di 0,15 su una LAN provoca tipicamente, al massimo, qualche decina di millisecondi di ritardo; quindi, si puó trascurare il ritardo LAN. Tuttavia quando l'intensità del traffico tende a 1 (come è il caso del canale di accesso nella Figura), il ritardo su un link diventa molto grande e cresce senza limite.
Così, il tempo di risposta medio per soddisfare le richieste è dell'ordine dei minuti, se non di più, il che è inaccettabile per gli utenti dell'istituzione.
Una possibile soluzione è quella di aumentare la velocità di accesso da 15 Mbps, per esempio, a 100 Mbps. Questo abbasserà l'intensità del traffico sul link a 0.15, che si traduce in ritardi trascurabili tra i due router. In questo caso, il tempo di risposta totale sarà circa due secondi, cioè il ritardo Internet. Ma questa soluzione comporta anche che l'istituzione aggiorni la velocità del suo canale verso la rete pubblica da 15 Mbps a 100 Mbps, una proposta costosa.
Si consideri ora la soluzione alternativa di non aggiornare la velocità del canale, ma invece di installare una cache Web nella rete istituzionale. La frazione di richieste che vengono soddisfatte da una cache in genere varia tra 0,2 e 0,7. A scopo illustrativo, si supponga che la cache fornisca un tasso di successo di 0.4 per questa istituzione. Poichè i client e la cache sono collegati alla stessa LAN ad alta velocità, il 40 per cento delle richieste sarà soddisfatto quasi immediatamente, per esempio, entro 10 millisecondi, dalla cache. Tuttavia, ancora il restante 60 per cento delle richieste devono essere soddisfatte da parte dei server. Ma con solo il 60 percento degli oggetti richiesti che passano attraverso il canale, l'intensità del traffico sul link di accesso si riduce da 1,0 a 0,6.
Tipicamente, una intensità di traffico inferiore a 0,8 corrisponde ad un piccolo ritardo, approssimativamente, decine di millisecondi, su un collegamento a 15 Mbps. Questo ritardo è trascurabile rispetto ai due secondi di ritardo Internet. Alla luce di queste considerazioni, il ritardo medio è quindi:
0,4 · (0,01 secondi) + 0,6 · (2,01 secondi)
che è solo di poco superiore a 1,2 secondi. Così, questa seconda soluzione prevede un tempo di risposta ancora più basso rispetto alla prima soluzione, e non richiede che l'istituzione aggiorni il suo collegamento ad Internet. L'istituzione, ovviamente, deve acquistare e installare una cache web. Ma questo costo è basso.
Attraverso l'uso di reti per la distribuzione di contenuti (CDN), le cache Web svolgono un ruolo importante in Internet. Una società CDN installa molte cache distribuite su Internet, rendendo locale gran parte del traffico. Ci sono CDN condivise (come Akamai e Limelight) e CDN dedicate (come Google e Microsoft).
Il GET condizionale
Anche se il caching può ridurre i tempi di risposta percepiti dagli utenti, si introduce un nuovo problema - la copia di un oggetto che risiede nella cache potrebbe non essere più valida. In altre parole, l'oggetto ospitato nel server Web potrebbe essere stato modificato dopo che la copia è stata memorizzata nella cache del client. Fortunatamente, HTTP ha un meccanismo che permette ad una cache di verificare se gli oggetti sono aggiornati. Questo meccanismo è chiamato il GET condizionale. Un messaggio di richiesta HTTP è un cosiddetto messaggio GET condizionale se (1) il messaggio di richiesta utilizza il metodo GET e (2) il messaggio di richiesta include una riga di intestazione If-Modified-Since:. Per illustrare come funziona il GET condizionale, si propone un esempio.
In primo luogo, per conto di un browser, una cache (un proxy server) invia un messaggio di richiesta a un server Web:
GET /frutta/kiwi.gif HTTP/1.1 Host: www.cucinaesotica.comSecondo, il server Web invia alla cache un messaggio di risposta contenente l'oggetto richiesto:
HTTP/1.1 200 OK Date: Sat, 8 Oct 2011 15:39:29 Server: Apache/1.3.0 (Unix) Last-Modified: Wed, 7 Sep 2011 09:23:24 Content-Type: image/gif (… dati …)La cache inoltra l'oggetto al browser, ma memorizza l'oggetto anche nel suo disco locale. È importante sottolineare che la cache memorizza anche la data dell'ultima modifica dell'oggetto.
Terzo, una settimana dopo, un altro browser richiede lo stesso oggetto tramite la cache, e l'oggetto è ancora nella cache. Nel frattempo questo oggetto potrebbe essere stato modificato, per questo la cache esegue un controllo sulla data generando un GET condizionale. In particolare, la cache invia:
GET /frutta/kiwi.gif HTTP/1.1 Host: www.cucinaesotica.com If-modified-since: Wed, 7 Sep 2011 09:23:24Si noti che il valore della riga di intestazione If-modified-since: è esattamente uguale al valore della riga di intestazione Last-Modified: che è stata inviata dal server una settimana prima. Questo GET condizionale sta dicendo al server di inviare l'oggetto solo se questo è stato modificato dopo la data indicata. Si supponga che l'oggetto non sia stato modificato dal 7 settembre 2011 09:23:24.
Infine, il server Web invia un messaggio di risposta alla cache:
HTTP/1.1 304 Not Modified Date: Sat, 15 Oct 2011 15:39:29 Server: Apache/1.3.0 (Unix) (sezione body vuota)Si vede che in risposta al GET condizionale, il server Web invia ancora un messaggio di risposta, che però non include l'oggetto richiesto. Se si fosse incluso anche l'oggetto richiesto si sarebbe sprecata banda e sarebbe aumentato il tempo di risposta percepito dagli utenti, soprattutto se l'oggetto è grande. Si noti che questo ultimo messaggio di risposta contiene 304 Not Modified nella riga di stato, che indica alla cache che può continuare e, quindi, deve trasmettere la sua copia dell'oggetto contenuto nella cache (la cache del proxy) al browser richiedente.
Proxy Server.
Un proxy server è un programma che si interpone tra un client e un server inoltrando le richieste e le risposte dall'uno all'altro.
Il client si collega al proxy e gli invia le richieste, il proxy si collega al server e inoltra la richiesta del client, riceve la risposta e la inoltra al client. Per l'applicazione server, il client è il proxy server.
I proxy si possono dividere in proxy di applicazione e proxy a livello di circuito.
I proxy di applicazione lavorano a livello di applicazione e sono specifici per certi protocolli. Il proxy di applicazione più comune è il proxy server che gestisce l'accesso al Web.
I proxy a livello di circuito sono più flessibili perchè non sono specifici per un singolo protocollo, ma funzionano per qualsiasi servizio; si limitano ad effettuare un tunnel tra client e server. I proxy a livello di circuito sono anche semplici da implementare.
Il proxy può essere usato per:
connettività: permette a una rete privata di accedere all'esterno, o meglio a un client e un server che appartengono a due reti diverse di stabilire una connessione anche quando non è disponibile un instradamento diretto (routing) tra le reti; un computer con due interfacce, una verso la rete interna e una verso Internet, viene configurato in modo che faccia da proxy tra gli altri computer e Internet; si ha un unico computer connesso all'esterno, che però permette a tutti gli altri di accedere a Internet; è un modo per gestire gli accessi a Intemet dalle stazioni di una rete locale che non richiede la presenza di un router nella rete; di solito in questo caso il proxy viene usato anche come firewall;
caching: memorizza i risultati delle richieste in modo da migliorare le prestazioni; offre due vantaggi principali: l'accesso rapido alle risorse già accumulate nella cache e la riduzione del traffico nella rete che precede il proxy stesso;
controllo: può applicare regole per determinare quali richieste inoltrare o rifiutare e limitare l'ampiezza di banda usata dai client;
monitoraggio: permette di tenere traccia delle operazioni effettuate da una stazione, identificata dal suo indirizzo IP, o da un utente, identificato dall'account con cui si è autenticato (anche se ciò può creare problemi di privacy);
Nota: II proxy usato per offrire connettività ad Internet può richiedere obbligatoriamente l'autenticazione; in questo modo possono accedere ad Internet solo utenti autenticati ed è possibile registrare le operazioni compiute da ciascun utente.
Sicurezza: nasconde lo schema di indirizzi della rete interna e quindi rende più difficoltoso l'accesso agli intrusi; sulla rete locale si possono usare gli indirizzi presi dagli intervalli di indirizzi privati; le reti esterne possono vedere solo l'indirizzo IP del proxy; tutte le conversioni fra rete interna ed esterna vengono gestite dal proxy;
privacy: maschera gli indirizzi IP del client; come indirizzo del client viene visto solo l'indirizzo dei proxy.
Quando il proxy viene usato principalmente per migliorare le prestazioni di un segmento di rete con l'uso della cache il proxy può essere installato su qualsiasi computer, basta che sia accessibile dal segmento di rete che lo deve utilizzare e che a sua volta sia in grado di accedere all'esterno.
Se il proxy viene usato per offrire connettività, deve essere installato su un computer con almeno due interfacce, una connessa alla rete locale con indirizzi privati e una connessa alla rete esterna; in questo modo permette ai client della rete privata di avere accesso all'esterno attraverso il proxy stesso. L'accesso si limita ai protocolli gestiti dal proxy (usando un proxy di applicazione spesso si tratta solo di HTTP e FTP).
II proxy può ricoprire anche un ruolo di filtro e inoltro di pacchetti tra la rete privata e la rete esterna. Per usare un proxy si può configurare il client in modo che si colleghi al proxy, oppure configurare il NAT in modo da realizzare un servizio di proxy trasparente (facendo in modo che le connessioni vengano indirizzate automaticamente al proxy).
PROXY HTTP
L'utente usa normalmente il browser per visitare pagine Web su Internet; le richieste vengono effettuate tramite il server proxy, che riceve le risposte e le invia al browser interessato. Quando effettua una richiesta il server proxy memorizza le risorse ricevute in una cache per future richieste dello stesso o di altri client; questo permette di ridurre il traffico verso l'esterno migliorando le prestazioni (comunque non bisogna dimenticare che tutti i dati in ingresso vengono elaborati due volte, una dal proxy e una dal client e questo può rallentare le prestazioni). L'uso del server proxy permette anche di controllare le richieste che possono essere effettuate (per esempio a quali siti è consentito e a quali siti è vietato accedere.) e di tenere traccia delle operazioni effettuate, per esempio di tutte le pagine web visitate.
Qui termina la discussione su HTTP, un protocollo Internet (del livello applicazione). Si è visto il formato dei messaggi HTTP e le azioni intraprese dal client e dal server quando ricevono uno di tali messaggi, Si è anche visto come questi messaggi vengono inviati e ricevuti. Si è fatto anche cenno ad un po' di infrastruttura applicativa del Web, tra cui cache, cookie e database di back-end, che sono tutti legati in qualche modo al protocollo HTTP.