
Per trovare un elemento in un insieme vengono utilizzati gli algoritmi di ricerca. Questi algoritmi si dividono in due grandi categorie: ricerca a trasformazione di chiave e ricerca a confronto di chiave.
Questo tipo di ricerca utilizza una particolare funzione: la funzione HASH che trasforma la chiave in un indirizzo.
Esistono vari algoritmi HASH:
AMO diventa A=1000001, M=1001101, O=1001111 Queste stringhe vengono concatenate in un'unica stringa 100000110011011001111 e poi se ne prende una sua sottosequenza come 0110011 che, in base 10, rappresenta l'indirizzo della chiave

Trattamento delle collisioni
I criteri di trattamento delle collisioni si basano sull'individuazione di posizioni libere della tabella in modo da allocarvi la chiave collidente:
hi = [h0(k) + q(i)] mod N con 1<=i<=N-1
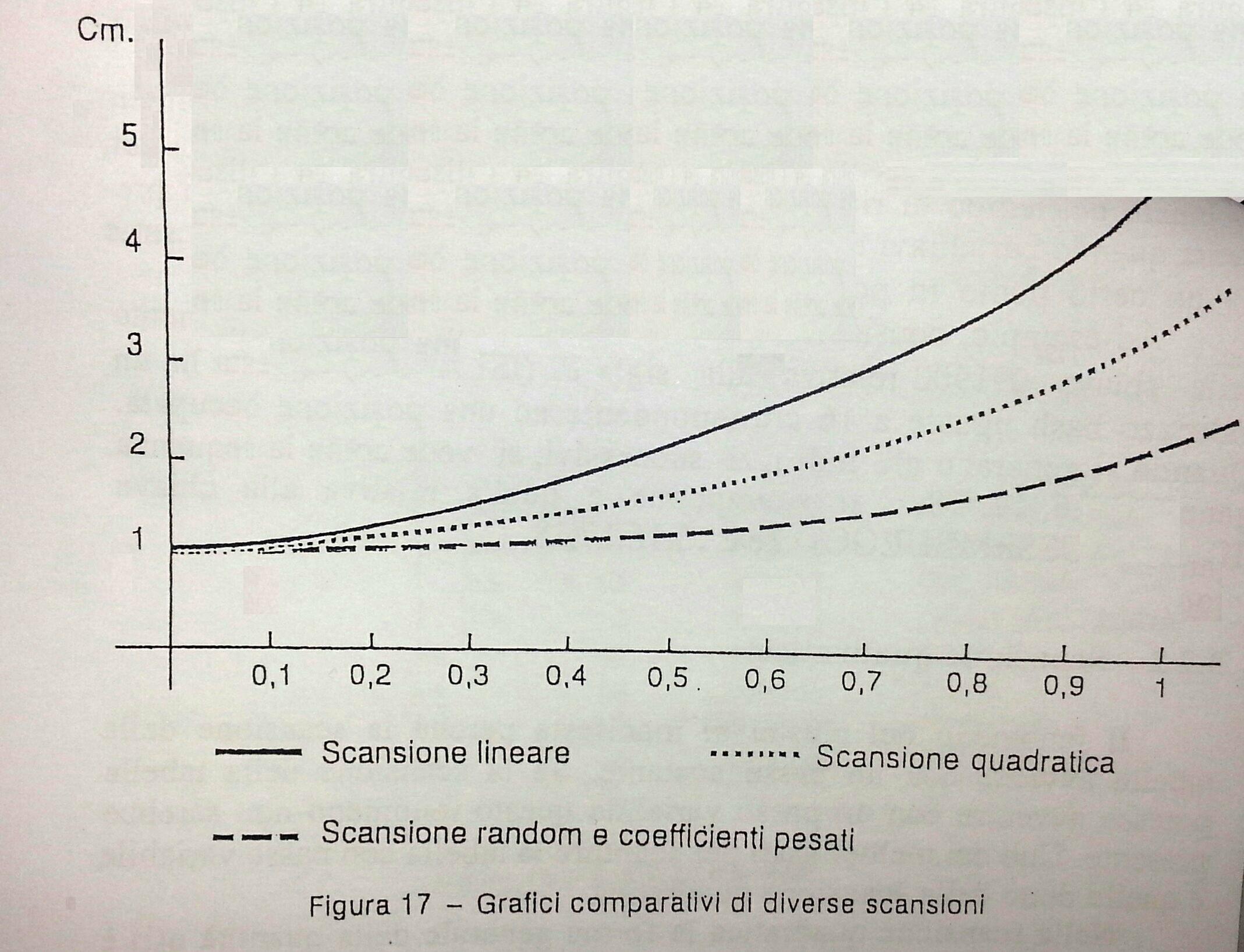
Scansione Lineare
La scansione lineare pone q(i) = i x c dove 'c' e' un numero scelto in modo da essere primo con l'ampiezza della tabella, cioe' MCD(N,c) = 1 .
Questa scelta di 'c' da' la garanzia che gli indirizzi generati ispezionano tutte le posizioni della tabella. Scegliendo c = 1 la scansione lineare,
nel caso di collisione cerca il posto libero nella posizione successiva.
Un difetto della scansione lineare e' il fenomeno dell' agglomerazione (clustering delle chiavi) che comporta un aumento del tempo di ricerca di una chiave
causato dai continui reHash. Il fenomeno del cluster si manifesta perche' la scansione della tabella avviene con passo costante.
Se la scansione della tabella potesse avvenire in modo variabile questo fenomeno non sarebbe presente.
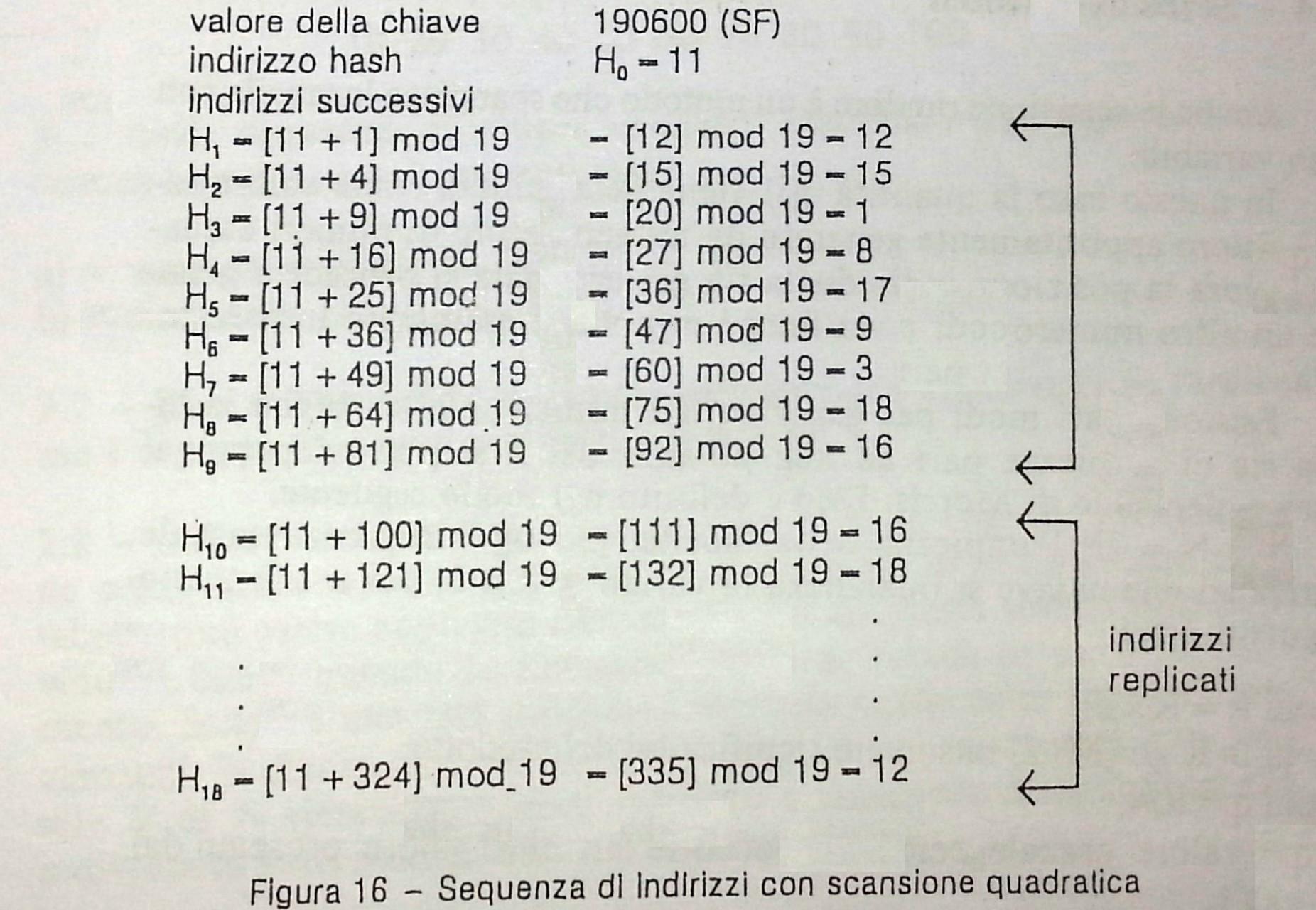
Scansione Quadratica
Uno dei modi usati per la scandire la tabella con passo variabile è detto scansione quadratica. Nella scansione quadratica il re-hash è dato da:
hi = [h0(k) + q(i)] mod N
con 1<=i<=N-1 e q(i)= a*i2 + b*i
('a' e 'b' sono costanti a piacere purché a !=0 cioe' a diverso da 0).
La scansione quadratica presenta due incovenienti:
L'algoritmo di ricerca lineare e' uno degli algoritmi di ricerca piu' semplici. Si confronta la chiave di ricerca k con ciascuna chiave dell'elenco. Se k risultera' uguale ad almeno una chiave presente nell'elenco la ricerca e' con successo (restituisce la prima poszione in cui e' stata trovata la chiave di ricerca). Se al termine di tutti i confronti la chiave di ricerca non e' stata trovata la ricerca e' senza successo (restituisce -1).

Nel caso medio, il numero di confronti da effettuare è uguale al rapporto tra la somma di tutti i possibili
confronti (1+2+3+...N) e il numero di elementi dell'insieme (N).
Ricordando che la somma dei primi N numeri naturali e' data dalla formula N(1+N)/2 (il primo numero piu' l'ultimo
per il numero degli elementi diviso due) si ha:
(1+2+3+...N) = N(1+N)/2
La media e': (1+2+3+...N)/N = N(1+N)/2N = (1+N)/2
L'algoritmo di ricerca lineare in un insieme ordinato e' una variante dell'algoritmo di ricerca lineare in un insieme non ordinato. Si confronta la chiave di ricerca k con ciascuna chiave dell'elenco. Se k risultera' uguale ad almeno una chiave presente nell'elenco la ricerca e' con successo (restituisce la prima poszione in cui e' stata trovata la chiave di ricerca). Nel mentre la chiave di ricerca k e' maggiore o uguale alla chiave presa in considerazione per il confronto e non sono stati effettuati tutti i confronti possibili, prosegui con la chiave successiva. Al termine del ciclo se la chiave di ricerca k e' uguale alla chiave presa in considerazione la ricerca e' con successo altrimenti e' senza successo.

Nota: l'algoritmo di ricerca lineare in un insieme ordinato è vantaggioso rispetto a quello di ricerca lineare in un insieme non ordinato nel caso in cui la ricerca è senza successo e il ciclo di confronti termina prima di giungere all'ultima posizione, perchè la chiave di ricerca k è minore della chiave presa in considerazione.
L'algoritmo di ricerca binaria opera su un insieme ordinato di elementi. Si confronta la chiave di ricerca k con la chiave che occupa la posizione centrale dell'insieme che chiameremo chiave centrale:
