I LIVELLI DI RETE E DI TRASPORTO
INTERCONNESSIONE LOCALE DI RETI
Per interconnettere più reti locali possono essere utilizzati, oltre agli HUB, i BRIDGE e gli SWITCH:
- - un HUB rappresenta un concentratore, ovvero un dispositivo di rete che trasmette tutte le informazioni che riceve su tutte le porte.
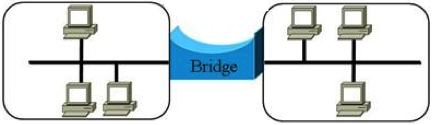
- un Bridge unisce due reti locali espandendo il raggio di azione di esse. È in grado di suddividere una grossa e popolosa LAN in più LAN per ridurre localmente le collisioni. Il Bridge è in grado di ritrasmettere solo i frame che devono passare da una rete all'altra, mantenendo separato il traffico locale della singola LAN. In questo modo il traffico locale delle due reti rimane separato (cioè esistono due domini di collisione). Per questo motivo i bridge sono dotati di opportuni di opportuni buffer che memorizzano i frame in arrivo prima del loro inoltro (modalità Store and Forward). Il bridge, per inoltrare i frame nel modo corretto, deve utilizzare delle tabelle di instradamento che contengono tutte le informazioni relative ad ogni possibile destinazione. Nei cosiddetti trasparent bridge, al momento della prima connessione alla rete, la sua tabella di instradamento è inizialmente vuota; nel momento in cui arriva un frame da una stazione ancora sconosciuta, il bridge provvede ad inoltrarlo a pioggia su tutte le sue uscite in modo da recapitare in ogni caso il frame e, nel contempo, inserisce l'indirizzo della stazione mittente nella tabella. Man mano che le altre stazioni inviano i frame, il bridge provvede ad aggiornare la tabella.
- - uno Switch è l'evoluzione moderna dei bridge e svolge le stesse funzioni, ma con la differenza che possiede molte più porte.
- Lo Switch può operare in 4 modi differenti:


Modalità operativa |
Caratteristiche |
Store-and-forward Switching |
Il frame viene memorizzato e controllato prima dell'invio |
Cut-Through Switching |
Il frame viene inoltrato immediatamente senza controllo |
Fragment-Free Switching |
Il frame viene controllato parzialmente (i primi 64 byte) |
Adaptive Switching |
Si adatta ad una delle tre modalità in base al traffico |
ANALISI DEI COSTI DEGLI SWITCH
FOTO |
PRODOTTO |
PORTE |
CARATTERISTICHE |
PREZZO |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




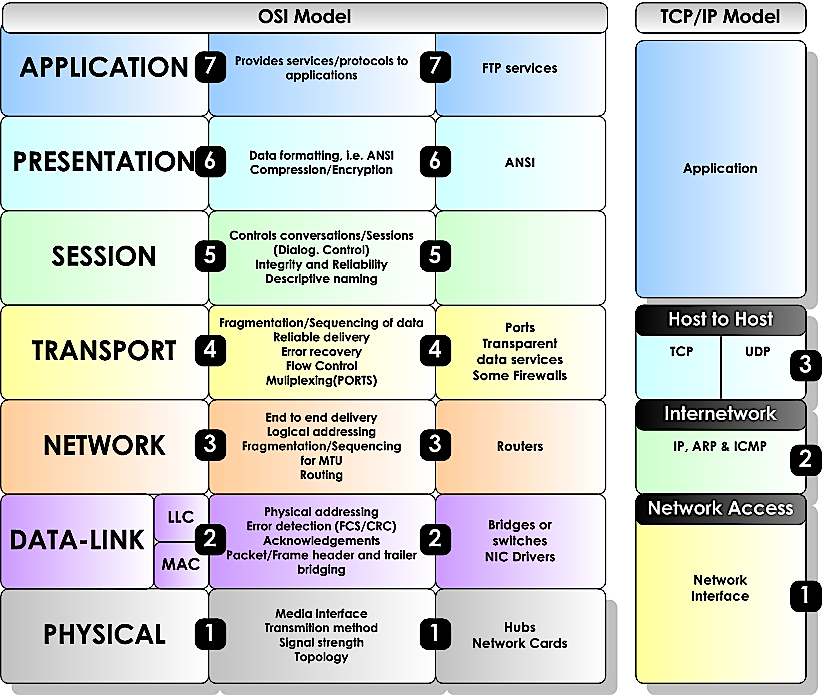
FUNZIONI DEL LIVELLO DI RETE

Le reti geografiche coprono un'area molto vasta ed i sistemi (End System), che accedono a tali reti, sono collegati tra loro attraverso dei nodi di commutazione (Intermediate System), detti router, e da linee che uniscono i diversi nodi. Potendo esserci, per i dati, percorsi alternativi, ogni router ha il compito di instradare i messaggi ricevuti in ingresso sulla opportuna linea d'uscita. I router, a differenza dei bridge e degli switch che lavorano a livello Data Link, sono dispositivi che lavorano a livello di Rete, infatti questi dispositivi sono in grado di estrarre il pacchetto dal frame ed utilizzare l'indirizzo del pacchetto per decidere dove inoltrarlo. Esistono due modalità differenti di far viaggiare i pacchetti attraverso i router intermedi che sono la conseguenza di due diversi tipi di servizi che lo strato di Rete può offrire allo strato di Trasporto:
- con il servizio senza connessione, i pacchetti sono inoltrati nella sottorete individualmente e possono seguire ognuno percorsi diversi. Pertanto non vi sono garanzie sull'arrivo. Un servizio di questo tipo viene detto best effort, poiché la rete "fa del proprio meglio, ma non garantisce niente". Tale sistema di comunicazione non è quindi affidabile ed ogni controllo deve essere effettuato dal computer di destinazione (End System) che dovrà riordinare la corretta sequenza dei pacchetti in arrivo. Ogni router memorizza al proprio interno una tabella d'instradamento che utilizza e aggiorna dinamicamente per inoltrare i pacchetti in base alle decisioni prese per mezzo di algoritmi che permettono di scegliere il miglior percorso disponibile in quel momento. Tali algoritmi sono appunto detti algoritmi di routing. Il servizio senza connessione, a datagrammi, è utilizzato da Internet.
- - Vantaggio: Robustezza, cioè le stazioni possono continuare a comunicare, anche se alcuni nodi non funzionano;
- Svantaggio: Inaffidabilità, poiché non ci sono garanzie circa la correttezza e la sequenzialità dei pacchetti ricevuti.
- con il servizio orientato alla connessione, il percorso viene scelto al momento della connessione formando un CIRCUITO VIRTUALE. Ogni pacchetto contiene al suo interno un codice che identifica il circuito virtuale cui appartiene e ogni router memorizza nella propria tabella l'elenco dei circuiti virtuali. Nel momento in cui termina la connessione, viene rimosso il circuito virtuale dalla tabella dei router.
- - Vantaggio: è garantita la sequenzialità dei pacchetti e la commutazione è più rapida perché ogni nodo non deve ricalcolare il percorso;
- Svantaggio: Minore robustezza, poiché in caso di nodi non funzionanti occorre ricalcolare e ristabilire tutto il percorso.
IL ROUTER E GLI ALGORITMI DI INSTRADAMENTO
I compiti di un router sono:
- - Routing: viene individuato il miglior percorso, calcolata ed aggiornata la tabella di instradamento tramite l'algoritmo di routing;
- - Inoltro: all'arrivo di un pacchetto viene consultata la tabella di instradamento e viene effettuato l'inoltro su una linea di uscita verso il nodo successivo.
Per l'individuazione del miglior percorso vengono adottati alcuni criteri, quali:
- - la distanza tra router adiacenti;
- - il traffico medio lungo la linea che collega i due nodi;
- - il costo delle diverse tratte, ecc…
Esistono vari algoritmi di routing che vengono raggruppati in due categorie principali:
- Non adattivi (statici): sono algoritmi che non tengono conto del traffico. A questa categoria appartengono gli algoritmi:
- Fixed directory routing: il gestore scrive manualmente nel router la tabella di instradamento; tale algoritmo non è consigliato per le reti di grandi dimensioni.
- Flooding: il pacchetto in ingresso su una linea del router viene inoltrato "a pioggia" su tutte le altre sue linee; questo algoritmo appesantisce la rete, però aumenta la probabilità che il pacchetto giunga a destinazione.
- Adattivi (dinamici): il criterio utilizzato si basa sulla topologia della rete e sul traffico. A questa categoria appartengono gli algoritmi:
- Routing centralizzato: vi è un router supervisore (RRC: Routing Control Center) che, acquisendo informazioni dagli altri router circa i collegamenti, viene a conoscenza della topologia di tutta la rete, provvede a calcolare le tabelle di instradamento e le distribuisce a tutti i router;
- Routing isolato: un algoritmo di esempio è l'HOT POTATO (Patata bollente), che prevede che ogni router invii sulla prima linea di uscita libera ogni pacchetto che riceve in modo da liberarsene quanto prima; un altro esempio è il backward learning che prevede che quando il router viene collegato alla rete per la prima volta, la sua tabella inizialmente è vuota; nel momento che arriva un pacchetto da un altro router ancora sconosciuto, il router provvede ad inoltrarlo a pioggia su tutte le sue uscite in modo da recapitare in ogni caso il pacchetto e, nel frattempo, inserisce l'indirizzo mittente nella tabella;
- Routing distribuito: tutti i router partecipano alla costruzione delle tabelle. Esempi: routing distance vector e routing link state packet.
- - Routing distance vector: ciascun router invia ai nodi adiacenti le informazioni
necessarie per la costruzione della tabella di instradamento che è
formata da un insieme di quattro campi per ogni nodo della rete da raggiungere:
Indirizzo Destinatario
N° dei nodi da attraversare (hops)
Somma dei costi delle linee (costo)
Porta su cui inviare il pacchetto (porta)
Due router adiacenti si scambieranno le informazioni relative al proprio distance vector, composto dalle prime tre colonne delle rispettive tabelle (indirizzo, hops e costo).
- Routing link state packet: ogni nodo deve conoscere la mappa completa della rete, costruita tramite l'invio di pacchetti denominati Hello. In seguito vengono inviati altri pacchetti speciali denominati Echo per misurare il tempo di risposta di ogni router adiacente e quindi stimare il costo dei collegamenti. Per ogni router si costruiscono i Link State Packet LSP, pacchetti che contengono l'elenco dei nodi adiacenti e i rispettivi costi dei collegamenti. Ogni router, predisposto il proprio LSP, provvede a inoltrarlo a pioggia verso gli altri nodi, con un algoritmo di flooding. Raccogliendo tutte queste informazioni, ogni router può predisporre l'LSP Database, uguale per tutti i nodi e rappresenta tutti i router dell'intera rete ed i collegamenti tra questi con i rispettivi costi. L'LSP Database è lo strumento che verrà utilizzato da ogni router per calcolare la propria tabella d'instradamento servendosi di un particolare algoritmo noto con il nome di algoritmo di Dijkstra. Tale algoritmo permette di stabilire il miglior percorso, cioè a costo minore, tra due nodi qualsiasi della rete. A tal fine si associa ad ogni nodo, ad eccezione di quello di partenza che viene considerato il primo working node WN (nodo di lavoro), una coppia di (c,n) dove c sta per costo ed n per nodo, che viene inizializzata con i valori (∞, *). Successivamente al posto di ∞ si sostituisce il costo del nodo di provenienza (con costo minore) e al posto di * si sostituisce il nome del nodo, passando quindi per i vari nodi, fino ad arrivare a quello di destinazione. Poi si procede a ritroso e si decide il percorso ottimale.
- Routing gerarchico: se l'ordine di grandezza del numero dei nodi che compongono la rete è elevatissimo, conviene suddividerla in regioni, e lasciare solo a pochi nodi della regione l'incarica di inoltrare i pacchetti verso le altre regioni. Esistono quindi due livelli gerarchici di routing: uno più elevato, inter-area, che coinvolge i router che possono inoltrare nelle regioni adiacenti ed uno più basso che coinvolge tutti gli altri router che possono inoltrare, intra-area, solo dentro le rispettive regioni. Il vantaggio che si ottiene è che ogni area ha dimensioni limitate e può essere gestita senza difficoltà dagli algoritmi descritti in precedenza.
IL CONTROLLO DELLA CONGESTIONE
Quando le stazioni immettono nella sottorete di comunicazione un numero tanto elevato di pacchetti da superare le capacità di trasporto di questa, alcuni nodi
non riescono più a reggere il traffico presente e non possono più garantire l'inoltro di tutti i pacchetti, generando quindi una congestione in una porzione
della sottorete. Le cause di una congestione possono essere: ad esempio quando un numero elevato di pacchetti provenienti da più porte di ingresso di un
router deve essere inoltrato su un'unica porta di uscita; oppure la modesta velocità della CPU interna ad un router nell'esecuzione dei tipici compiti di
aggiornamento delle tabelle o di accodamento dei pacchetti nel buffer.
INTERNET PROTOCOL SUITE
Alla base dell'enorme successo ottenuto da Internet in tutto il mondo, vi sono protocolli che sostituirono durante gli anni '70 il vecchio protocollo NCP
(Network Control Protocol), utilizzato inizialmente. Alla fine degli anni '70, infatti, venne adottata come standard della rete ARPANET, progenitrice di
internet, la INTERNET PROTOCOL SUITE, che comprendeva una serie di protocolli, i più famosi dei quali erano e sono tutt'ora, l'IP (Internet Protocol) ed il
TCP (Trasmission Control Protocol). Le cause del cambiamento furono:
- - la necessità di definire uno standard di comunicazione per l'interconnessione di computer di produttori diversi, gestiti da S.O. differenti;
- - la necessità di introdurre standard "de-facto" per evitare la proliferazione di protocolli proprietari che non avrebbero permesso l'interfacciamento tra sistemi di produttori diversi.
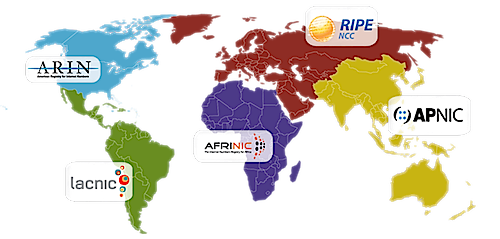
COMUNICAZIONE TRA PROTOCOLLI Registry Area Coperta AfriNIC Regione Africa APNIC Regione Asia / Pacifico ARIN Regione Nord America LACNIC America Latina e alcune isole caraibiche RIPE NCC Europa, Medio Oriente e Asia Centrale Un'altra distinzione che viene fatta per gli indirizzi IP è la seguente:
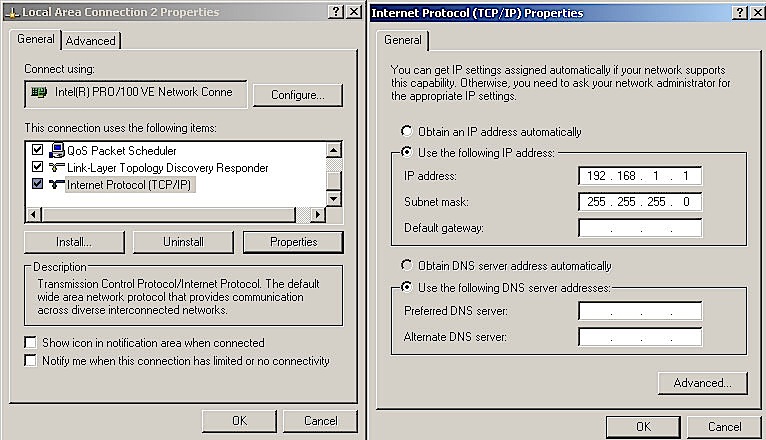
- Statico: quando un indirizzo viene assegnato permanentemente ad un host; - Dinamico: quando l'indirizzo viene assegnato temporaneamente ad un host.
In questo caso è un server DHCP del provider, opportunamente configurato, che provvede ad inviare un indirizzo IP tra quelli disponibili
all'host del cliente all'atto della connessione. L'indirizzo IP è composto da:
SUBNETTING Per indicare il tipo di classe della subnet mask, si può usare la "slash notation":
Dalla subnet mask si deduce facilmente il numero massimo di host presenti nella subnet considerata: 2n-2 dove:
Per determinare il numero massimo di indirizzi utili in una subnet basta contare il numero n di bit 0 a destra della subnet mask,
porre n come esponente di 2, e sottrarre a ciò i due indirizzi riservati (uno indica la sottorete stessa, l'altro è usato per fare
broadcast). La formula è dunque: 2n–2. Nel primo caso deve essere utilizzato un protocollo di trasporto orientato alla connessione, che permette il controllo di flusso e la
correzione di errori; nel secondo caso può essere utilizzato un protocollo di trasporto non orientato alla connessione. La Internet
Protocol Suite prevede l'utilizzo alternativo del TCP (orientato alla connessione) o dell'UDP (non orientato alla connessione).
Protocollo IP del mittente Porta mittente IP destinazione Porta destinazione Formato dalla coppia di socket sorgente e destinazione. Quando il TCP riceve da un'applicazione del livello superiore una sequenza di byte, la
memorizza temporaneamente in un buffer per dividerla, se necessario, in blocchi più piccoli detti segmenti TCP.
La lunghezza massima utile del frame viene detta MTU (Maximum Transfer Unit). Anche i segmenti TCP sono
formati da un'intestazione di dimensione variabile e da un campo dati la cui dimensione massima detta
MSS (Maximum Segment Size) si ottiene sottraendo alla MTU i 20 byte di intestazione IP e di 20 byte di intestazione TCP.
L'insieme di
INDIRIZZI IP
Ad ogni interfaccia di rete di ogni apparato che utilizza il TCP/IP, sia un router o una scheda di rete di un PC o qualsiasi altro dispositivo,
viene assegnato un indirizzo logico di dimensione fissa pari a 4 ottetti (32 bit). Esistono 2 categorie di indirizzi IP:
La subnet mask è un insieme di tecniche usate per dividere l'intera rete in sottoreti, al fine di ridurre il traffico di rete.
Esistono tre tipi di mascherature di un indirizzo IP e sono denominate classi:
Quando il livello IP riceve da un programma la richiesta di inviare un pacchetto IP ad un certo indirizzo IP destinatario, per prima cosa calcola
l'AND logico fra la subnet mask e il proprio indirizzo IP, e lo confronta con l'AND logico tra la subnet mask e l'indirizzo IP di destinazione.
Se il risultato delle operazioni è identico, allora invierà il pacchetto nella rete locale indirizzandolo con l'indirizzo di rete locale del
PC destinatario; se invece il risultato delle operazioni è differente significa che il computer destinatario non appartiene alla rete locale e
il pacchetto verrà trasmesso al gateway della rete locale affinché lo instradi verso la rete remota che contiene il computer destinatario.
PROTOCOLLI DI TRASPORTO IN INTERNET
Le applicazioni degli strati superiori possono richiedere due tipi di servizi allo strato di trasporto:
PROTOCOLLO TCP
Il TCP è un protocollo a finestra scorrevole con piggybacking. Prima della trasmissione dei dati occorre stabilire tra l'host mittente e
quello ricevente una connessione logica. Una connessione è caratterizzata da:




